
안녕하세요, 공우 14기 권태희입니다. 이번에는 전기정보공학부 프로젝트 과목의 꽃이라고 불리우는, 디지털 시스템 설계 및 실험 과목에 대해 소개드리려고 합니다.
1. 과목에서 배울 수 있는 내용
1.1 과목의 전반적인 개요
‘디지털 시스템 설계 및 실험’ 과목은 프로젝트의 주제이기도 한, Verilog와 FPGA를 통해, NPU의 한 종류라고 볼 수 있는 CNN accelerator를 설계하는 것을 최종 목표로 두고, 그에 필요한 지식들을 조금씩 배워나가는 과목입니다.
과목에서 배우는 내용을 크게 쪼개면, synthesizable verilog, FPGA, 하드웨어가 숫자를 다루는 방식, 그리고 NPU가 있습니다. 각 내용이 어떤 것들을 다루는지, 하나씩 설명드리도록 하겠습니다.
*본 글은 전기정보공학부 로드맵 상에서 선이수과목으로 지정된 ‘논리설계 및 실험’ 수강을 통해, 독자께서 기본적인 Verilog 문법, logic gate, MUX, flip-flop 등을 알고 있다는 가정하에 작성하였음을 미리 말씀드립니다. 양해 부탁드립니다.
*LAB 수업시간에 조금씩 배우게 되는 AXI, UART protocol 등 세부적인 지식은 본 글에서는 다루지 않았습니다.
1.2 키워드 별 개념 설명
1) “Synthesizable” Verilog
- Three types of modeling: Structural, Dataflow, Behavioral
Verilog는 HDL, Hardward Description Language의 한 종류로, 말 그대로 “하드웨어를 기술하는” 언어입니다. 사용하는 문법은 C언어의 것을 차용하여 어느 정도 익숙하지만, 코드를 작성할 때 머릿속에 넣어두어야 하는 것은 완전히 다르다고 할 수 있습니다. C언어, Python 등 많이 접해보셨을 프로그래밍 언어들은 보통, 특정 동작을 수행하도록 지시하는 코드를 작성합니다. 그러나 Verilog와 같은 HDL은, 특정 동작을 수행할 수 있는 “hardware”를 설계하고, 그 하드웨어를 “describe”하는 방식으로 코드를 작성하게 됩니다. Verilog 코드는 하나의 ‘모듈‘을 작성하는데요, 모듈이 input을 받아 output을 내보내도록 하는 일련의 동작을 수행하는 회로를 코드로 옮겨두었다고 볼 수 있습니다.
Verilog 코드를 작성하는 데는 level별로 크게 세 가지 방식이 있습니다. 간단한 논리회로(아래 그림 참고) Full Adder의 예시를 통해 이를 살펴보도록 하겠습니다.

첫 번째는 가장 low level의 방식으로, 회로를 구성하는 각 논리 게이트를 하나씩 지정해주고, 이를 연결하는 wire 또한 하나씩 직접 작성해주는 방식입니다. 이를 structural modeling이라 합니다.
module full_adder_structural(x, y, c_in, s, c_out);
input x, y, c_in;
output s, c_out;
wire s1, c1, c2, c3;
xor xor_s1(s1, x, y);
xor xor_s2(s, s1, c_in);
and and_c1(c1, x, y);
and and_c2(c2, x, c_in);
and and_c3(c3, y, c_in);
or or_cout(c_out, c1, c2, c3);
endmodule
두 번째는 그 다음 level로, 각 bit 간 연산이 흘러가는 방식을 operator를 통해 표현하게 됩니다. 이를 dataflow modeling이라 합니다.
module full_adder_dataflow(x, y, c_in, s, c_out);
input x, y, c_in;
output s, c_out;
assign s = x ^ y ^ c_in;
assign c_out = (x & y) | (x & c_in) | (y & c_in);
endmodule
마지막은, 최종적으로 각 wire/reg가 가져야 하는 ‘값’을 지정해주는 behavioral modeling입니다. 이름에서부터도 알 수 있듯, 실제 하드웨어의 구성을 낱낱이 작성하기보다는, high level에서 최종적으로 일어나야 하는 동작을 지정하는, C언어 등의 코드와 가장 유사한 작성 방식입니다. 여기서는 예시가 워낙 간단하여 dataflow modeling과의 차이가 두드러지지는 않았는데요, 복잡한 코드가 될수록 behavioral modeling이 편리한 경우가 있습니다.
module full_adder_behavioral(x, y, c_in, s, c_out);
input x, y, c_in;
output reg s, c_out;
always @(*) begin
s = x ^ y ^ c_in;
c_out = (x & y) | (x & c_in) | (y & c_in);
end
endmodule
실제 코딩을 하다 보면 dataflow 방식과 behavioral 방식을 많이 쓰게 될 텐데요, 코드를 low level로 작성할수록 하드웨어의 동작을 원하는 대로 정확하게 지정해줄 수 있다는 장점이 있지만, 또 그렇게만 짜다 보면 코드가 너무 복잡해지고 길어질 것이기에, add, multiply 등 기본 연산은 operator를 적극적으로 활용하여 작성해주는 것이 편리합니다.
- Verolog Coding Rules!
제가 단락에서 뽑은 키워드는, Verilog가 아닌 synthesizable verilog였습니다. ‘Synthesizable’, 번역하여 ‘합성 가능한‘이 어떤 의미인지는 FPGA에 대해 설명드리면서 더 명확해질텐데요, 대략만 말씀드리면 HDL 코드를 작성하고 이를 FPGA 등 하드웨어에 올려 동작시킬 수 있는 코드를 말합니다. 시뮬레이션을 성공했다고 해서 항상 합성 가능하지는 않습니다. 특정 코드가 합성되지 않는 정확한 이유는 프로그램의 합성 방식에 있겠지만, 안전하게 코딩을 진행하기 위해서는 몇 가지 규칙을 지켜야 합니다. 아래는 몇 가지 규칙(패턴)들을 정리한 것인데요, 이 정도 규칙은 알아두고 코딩을 하시는 것이 좋으며, 직접 부딪히며 알아가셔야 하는 부분들도 존재합니다. 이는 참고자료(3)을 기반으로 하였으며, 인용 조건으로 원본 pdf 또한 첨부하였습니다.
1) Combinational Logic을 구현하는 assign 구문
- Left operand는 wire
2) Combinational Logic을 구현하는 always 구문
- always @(*) 사용
- = 사용
- Left operand는 reg
3) Sequential Logic을 구현하는 always 구문
- always @(posedge clk, negedge rstn)
- <= 사용
- Left operand는 reg
2) FPGA
- What is FPGA?
FPGA는 Field-Programmable Gate Array의 약자로, 말 그대로 풀어 보면 논리 게이트를 프로그래밍할 수 있다는 뜻입니다. Verilog 등의 HDL 코드를 통해 원하는 하드웨어 설계를 기술하게 되면, 그 하드웨어가 칩 위에 구현되는 것이죠. 이것이 어떻게 가능한지 살펴보기 전에, FPGA 보드 위에 있는 다양한 구성 요소들에 대해 설명드리도록 하겠습니다.
- Components of FPGA
FPGA는 다양한 기능의 회로들로 구성되어 있습니다. 컴퓨터 등과 연결하여 사용할 수 있는 I/O 인터페이스부터, sequential circuit을 구현하기 위한 clocking element과 flip-flop, FPGA에 부착되어 있는 SRAM buffer로 이해할 수 있는 Block RAM(BRAM), 다양한 연산을 시행하는 ALU, 그리고 원하는 logic을 구현하는 데 사용되는 LUT 등이 아주 복잡하게 연결되어 있습니다.
이들 중 LUT에 대해 간단히 소개드리겠습니다. LUT는 lookup table의 약자로, 말 그대로 table에서 input 값을 찾으면 output 값을 알 수 있는 구조라 볼 수 있습니다. 아래 그림에서 푸른 음영이 있는 부분인데요, 모든 input의 경우의 수에 대해 원하는 output 값을 저장함을 통해, 원하는 logic을 구현할 수 있는 원리입니다. FPGA를 이루는 기본적인 logic block은 아래 그림과 같이, LUT를 사용하여 logic을 표현하고, 그 결과를 바로 사용하거나(combinational) clock에 맞추어 사용하거나(sequential)를 선택할 수 있는 구조로 되어있습니다. 이 모든 선택은 작성한 코드에 달려 있는 것이죠.

- Synthesis: How do Verilog codes get converted into a real circuit?
이제 Verilog과 같은 HDL로 작성한 코드를 synthesis한다는 것이 무슨 의미인지 짐작이 가시나요? 구현하고자 하는 하드웨어를 FPGA의 구성 요소들에 끼워 맞추는 과정입니다. 각각의 LUT와 MUX에 적절한 값을 넣기 위한 준비를 하는 전 과정은, 정말 다행스럽게도! Vivado와 같은 툴들이 저희를 위해 대신해주고 있습니다.
아래 그림은 FPGA의 logic block 일부를 이루는 ‘SLICEM’의 그림을 가져온 것인데요, 복잡하기는 하지만 제가 색으로 표시한 부분만 따라가보면, 앞서 살펴본 기본 구조를 가짐을 확인해볼 수 있습니다. 푸른 선은 LUT를 통해 output을 생성하는 부분, 분홍 선은 이를 combinational circuit으로 활용하는 부분, 주황 선은 sequential circuit으로 활용하는 부분입니다. 실제 FPGA는 이러한 logic block과 더불어 각종 arithmetic 연산을 담당하는 unit(DSP), shift 연산을 실행해주는 unit 등으로 구성되어 있습니다. 이제는 Verilog로 코딩을 하면서 단순히 원하는 동작을 만드는 데 그치지 않고, critical path의 길이, buffer의 크기, DSP 개수 등 하드웨어적인 한계를 고려하며 설계를 해야 하는 것입니다.

3) How does HW deal with numbers?
이번에는 하드웨어가 숫자를 어떤 방식으로 표현하고, 그들 사이의 연산을 어떻게 수행하는지에 대해 알아보려고 합니다. 수업에서는 다양한 표현 방식, multiplier 등 다양한 내용을 다루었지만, 본 글에서는 흥미로운 주제 한 가지만 꼽아 간단히 이야기해 보겠습니다.
- For Carry-free additions: only Rebundant Arithmetic here…
두 수의 덧셈을 진행한다고 생각해 봅시다. 우리는 십진수의 덧셈을 진행할 때, 가장 낮은 자릿수끼리 덧셈을 하고, 받아올림이 생긴다면 그를 다음 자리로 넘겨주는 과정을 반복하여 최종적인 결과를 얻습니다.

이 과정은 우리가 ‘한 자리수 + 한 자리수’ 덧셈을 하는 덧셈기를 연속적으로 사용하여 계산을 진행한 것으로 해석 가능합니다. 이 덧셈기는 입력으로 더해질 수 2개와 아랫자리에서 받아올림해온 값(0 또는 1)을 받아, 출력으로 윗자리로 받아올림 할 값과 그를 제외한 더해진 값을 내보냅니다. 위의 연산을 예로 들면, 이 덧셈기 6개를 활용하여 연산을 할 수 있습니다.
가능한 설계이지만, 이 방식의 단점은 연산이 매우 느리다는 것입니다. 일의 자릿수를 담당하는 덧셈기는 바로 9+9를 계산할 수 있지만, 백만 자릿수를 담당하는 덧셈기는 이전 자리로부터 받아올림이 준비될 때까지 기다려야 하는 것입니다. 매우 큰 두 수를 더하게 된다면 이 기다리는 시간이 더 길어지겠지요. 이처럼 받아올림, carry가 전파되는 경로는 덧셈기의 critical path가 되며, 그 성능과 직결됩니다. 이러한 carry path를 줄여서(‘거의’ 없애서) 더 빠른 덧셈을 하는 방식을 carry-free addition이라고 합니다. 한 가지 방법으로, rebundant arithmetic에 대해 간단히 소개드리려고 합니다.
Rebundant arithmetic은 말 그대로, ‘중복된 자릿수 표기’를 허용하는 것입니다. 예를 들어, 여전히 십진법을 사용하지만, 한 자릿수에 위치하는 수의 범위를 [0, 9]에서 [0, 18]로 한 번 바꾸어 보겠습니다. 이 경우, 위의 덧셈은 carry를 하나도 발생시키지 않고 다음과 같이 계산 가능합니다.
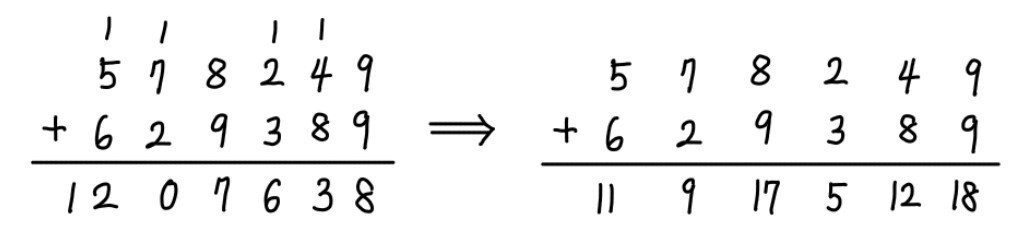
여기서 눈치챌 수 있는 점 두 가지는, 첫 번째, 같은 계산 결과의 표기 방식이 유일하지 않아졌다는 점, 그리고 이런 식으로 무한정 자릿수의 범위를 늘릴 수는 없다는 점입니다. 단순 덧셈으로는 문제가 발생하는 예시와 해결 방안을 하나 살펴보겠습니다.
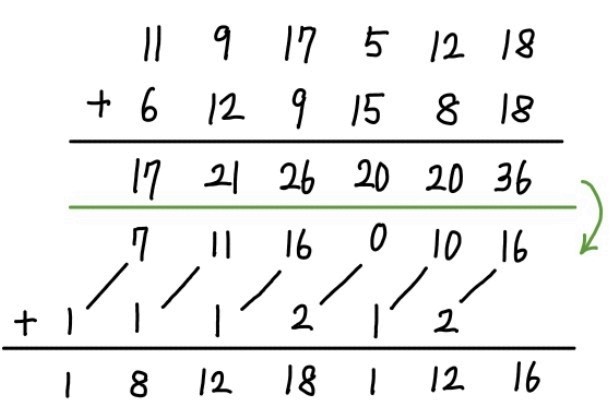
일단 자릿수별 덧셈을 진행한 뒤, 각 자릿수에서 넘치는 자리를 약간씩 윗자리로 받아올림해 주겠습니다. 이후, 자릿수별 덧셈을 한 번 더 진행하면, 더 이상 받아올림은 필요 없게 됩니다. 자릿수 범위를 적절히 조절해 주면, 이처럼 받아올림 횟수를 제한함으로써 덧셈 연산을 더 빠르게 수행할 수 있게 됩니다.
물론 이런 방식의 단점도 존재합니다. 허용하는 자릿수의 범위를 늘리면서, 하나의 숫자의 표기 방식이 유일하지 않아지게 되었습니다. 따라서, 이전에는 간단하던 두 수의 크기 비교(특히, 숫자 ‘0’과의 비교), 부호 판별, overflow 발생 여부 판단 등을 진행하는 데는 추가적인 cost가 발생하게 됩니다. 방식의 장단점을 잘 알아두고, 장점이 더 돋보적인 경우 잘 활용하면 좋을 것 같습니다.
4) NPU
드디어 과목의 꽃인 프로젝트, NPU로 넘어왔습니다. 우선, 본문에서는 ‘디지털 시스템 설계 및 실험’과 아주 직접적인 연관이 없는 딥러닝에 대한 기초 개념(neural network, forward/backward propagation)과 CNN(Conv layer, Pooling layer, FC layer)에 대한 개념 설명은 생략하였다는 점을 양해 부탁드립니다.
- Why need ‘hardware accelerators’?
어떠한 연산을 하는 프로그램을 실행시키고 싶다고 해봅시다. 보통의 경우에는 CPU를 이용하더라도 문제가 없습니다. CPU는 주어지는 모든 소프트웨어를 실행할 수 있는 범용적인 unit입니다. 만약, 동일한 계산만을 계속하여 반복시키는 프로그램을 CPU에게 시키는 것은 어떨까요? 물론 연산을 시행하는 것 자체에는 문제가 발생하지 않습니다. 그러나 앞으로 할 연산이 고정적으로 정해져 있음에도 불구하고, CPU가 반복적으로 instruction을 읽어오고, 한정된 computational resource로 연산을 한다면 계산이 꽤 느리겠지요. **‘Accelerator’**는 여기에서부터 출발합니다. CPU처럼 모든 소프트웨어를 실행할 수 있는 능력을 포기하고, 대신 반복적으로 실행할 프로그램을 dedicate해버린 이후, computational unit을 parallel하게 사용하여 더 빠르게 연산을 하는 것이지요. 이러한 장단점을 갖기에, CPU와 accelerator를 함께 사용하여 각각의 장점을 취하기도 합니다. Control intensive한 프로그램을 실행할 때는 CPU를 사용하고, compute intensive한 프로그램을 실행할 때는 CPU가 accelerator에게 실행을 명령하는 방식으로 시스템을 구성할 수 있습니다.
- What CNN is all about: matrix multiplication
이제 수업에서 가속하고자 하는 목표인 CNN이 얼마나 accelerator에 적합한지 살펴보도록 하겠습니다. 앞서 말씀드렸듯 accelrator가 그 역할을 제대로 해내려면, 반복적인 연산량이 많은 task를 target해야 합니다. CNN을 구성하는 layer는 크게 세 종류로, Convolution layer, Pooling layer, FC layer가 있습니다. 이때, Pooling layer는 전체 연산 시간에서 차지하는 비중이 매우 작기에, 논외로 하겠습니다.
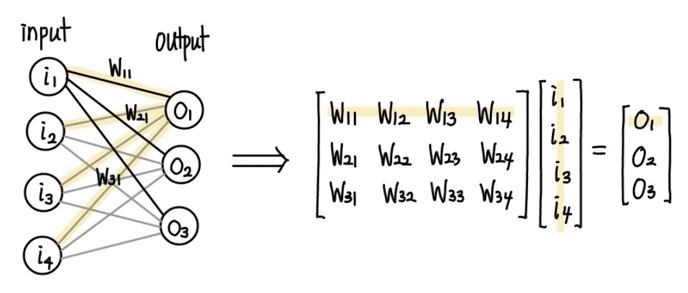
상대적으로 간단한 FC layer를 먼저 살펴보겠습니다. FC, fully connected layer의 연산(편의를 위해 bias를 생략하였습니다)은 아래 그림과 같이 행렬-벡터 곱으로 나타낼 수 있음을 확인해보실 수 있습니다. 벡터를 nx1 행렬로 본다면, 이 또한 행렬-행렬 곱으로 볼 수도 있는 것입니다.
다음으로 Convolution layer입니다. Convolution layer의 연산 과정을 for문으로 나타내면 무려 7중 for문이 되지만, 여기서는 ‘im2col’이라는 방식을 사용하여 연산 과정을 행렬-행렬 곱으로 바꾸어 보겠습니다. 아래 그림에서는 input feature size (3, 3, 3), filter size (3, 2, 2), filter 2개인 경우를 예시로 들었습니다.

정리하자면, CNN의 forward pass 과정에서는 사실상 ‘행렬곱’이 이루어지고 있으며, 행렬곱은 반복되는 곱셈 연산을 많이 실행하는 workload임을 확인 가능합니다. 이러한 특징 덕분에, accelerator가 neural network에서 빛을 발할 수 있는 것입니다.
- Systolic Array: only OS systolic array here…
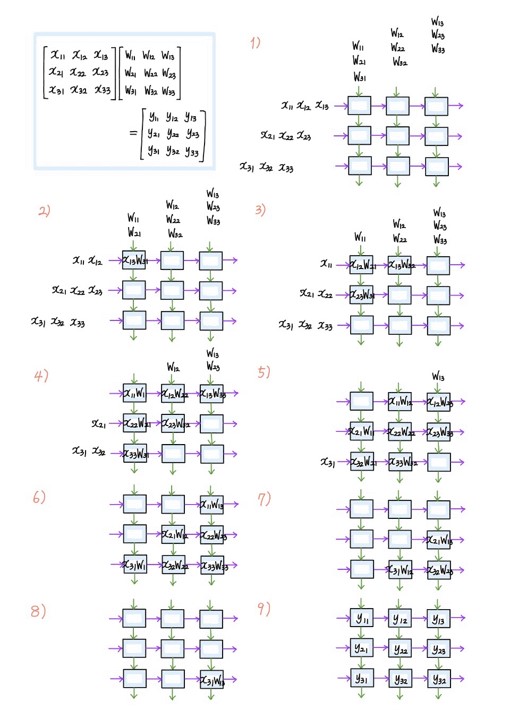
Accelerator에서 많이 사용되는 구조 중 하나인, (OS: Output Stationary) systolic array에 대해 설명드리면서 마치려고 합니다. Systolic array는 행렬 곱셈을 실행할 수 있는 하드웨어 구조로, 아래 그림과 같이 생긱 ‘systolic unit’이 이차원을 따라 배열되어 있는 형태를 갖습니다. Systolic unit은 내부에 누적합을 저장하는 register를 하나 가지고 있는데, 1 clock마다 두 개의 input을 곱하고, 곱한 값을 내부 누적합에 더하는 방식으로 연산을 진행합니다.

Systolic array의 사용 방법은, 곱셈을 할 두 행렬을 근처의 buffer에 저장시켜 두고, 1 clock이 지날 때마다 행렬 data를 다음과 같은 순서로 한 칸씩 흘려보내 주는 것입니다. Buffer에 저장되어 있던 data가 전부 systolic array를 통과하고 나면, 각 systolic unit에는 행렬곱 결과의 성분이 저장되게 됩니다. 자세한 과정은 아래 그림을 통해 이해해보시길 바랍니다.
Systolic array의 간단한 확장으로, double buffering을 생각해볼 수 있습니다. 행렬곱의 전체 과정이 buffer를 채우고, buffer의 값을 활용하여 연산을 진행하고, 또 다시 buffer를 채우는 것을 안 순간, pipelining을 도입해볼 수 있습니다. Buffer 두 개를 사용하여, 한 buffer에 저장된 값을 이용하여 연사을 진행하는 동안 다른 buffer에 다음으로 연산할 data를 채워두는 방식입니다. 수강생께서는 Buffer의 크기, systolic array의 크기 등이 바뀜에 따라 전체 실행 속도가 어떻게 변하는지 생각해보시고, 빠른 accelerator를 구현하는 데 집중해보시는 것도 좋을 것 같습니다.
워낙 다양한 지식들을 배우는 과목인지라, 큰 틀에서 설명하며 누락된 내용들이 많습니다. 생략된 내용들이 궁금하신 분들은 수업 수강을 추천드립니다!
2. 선배의 조언
1) 수강 순서 추천
디지털 시스템 설계 및 실험은 전기정보공학부 전공과목 로드맵에서 3학년 2학기 전공선택필수 과목으로 분류되어 있으며, 전공필수 과목인 논리설계 및 실험을 선이수과목으로 두고 있습니다. 그런 만큼, 논리설계 및 실험은 꼭 수강하신 후에 본 과목을 수강하시길 바랍니다. 처음으로 Verilog와 부딪히게 되며, 0과 1만을 다루는 하드웨어에 대한 기초적인 이해를 함양하실 수 있을 것입니다.
사실, 디지털 시스템 설계 및 실험(이하: 디시설)과 컴퓨터조직론(이하: 컴조) 사이에는 수강 순서를 둘러싼 약간의 논란(?)이 있습니다. 두 과목이 다루는 내용은 사실 꽤 다르지만, 공통적으로 Verilog를 다루고, 공유되는 개념이 존재하기 때문에 발생하는 것이라고 생각되는데요, 저는 3학년 1학기 컴조, 2학기 디시설을 수강한 입장으로 이에 대한 개인적인 의견을 말씀드리고자 합니다.
결론부터 말씀드리면, 어느 쪽이든 크게 상관 없을 것 같고, 장단이 존재하므로 편하신 대로 하시면 좋을 것 같습니다. 컴조를 먼저 들었을 때의 장점은, CPU가 동작하는 원리를 이해하고, pipelining이라는 개념을 이해한 상태로 디시설을 들을 수 있으며, Verilog simulation이 익숙한 상태에서 하드웨어(FPGA), 그리고 더 큰 프로젝트로 넘어갈 수 있다는 점입니다. 디시설을 먼저 들었을 때의 장점은, Verilog를 체계적으로 수업하는 첫 번째 수업이다 보니(…개인적으로는 이를 논리설계 및 실험에서 다루면 더 좋을 것 같지만), 컴조 과제를 진행함에 있어 Verilog 자체에 부딪히며 겪을 수 있는 시행착오를 월등히 줄일 수 있다는 점이고, 디시설을 먼저 듣는 것이 좋다고 하는 분들은 대부분 이를 큰 장점으로 꼽습니다.
추가적으로, 기계학습 기초 및 전기정보 응용/딥러닝의 기초/(수리과학부 과목이지만) 심층신경망의 수학적 기초 수강, 혹은 다양한 방법을 통해 딥러닝이 무엇이며, 어떤 식으로 진행되고, CNN은 무엇인지에 대한 기본적인 지식을 알고 있는 상태에서 수강하는 것을 추천드립니다. 물론, 잘 알지 못하더라도 accelerator 설계를 진행하는 데 필요한 정도의 지식은 수업시간에 다루게 될 것입니다. 그러나 자신이 설계하고 있는 모듈이 어떠한 기능을 하는 것인지 정도는 이해한 상태에서 구현을 진행하는 것이 더 깊은 이해를 하는 데 도움을 줄 것이라 생각합니다.
2) 프로젝트 진행 Tip
다음으로 프로젝트를 진행할 때의 몇 가지 팁을 드리고자 합니다.
- 전체 구조 그림 그리기
아마 프로젝트 파일을 처음 다운받아 Vivado 프로젝트를 열면, 당황스러우실 겁니다. 그동안 Verilog로 진행한 프로젝트들(논리설계 및 실험, 컴퓨터조직론)에 비하면 파일 수, 각 모듈 간 port 수가 몇 배가 되었을 것이기에, 사실 저도 처음에는 한숨부터 나왔습니다. 프로젝트 전반을 파악하는 데 도움이 되었던 것은 바로 그림을 그리는 것이었는데요, 모듈은 박스로, 포트는 선으로 연결하면서 전체 모습을 대략 나타내보면, 조금은 더 빨리 전체 구조를 파악할 수 있습니다. 구조를 파악하면서 작성해야 할 것이 어떤 모듈이고, 어떤 역할을 수행해야 하며, 전체 흐름이 연결되면서 최종적으로 계산이 진행되는 흐름을 아셔야 다음 단계로의 진행이 가능합니다.
- 테스트케이스 만들어 사용하기
프로젝트에서 구현하는 CNN이 다루는 feature size에 따라, 설계 방식에 따라서는 계산 방식이 조금씩 달라질 수 있습니다. 예를 들어, 제가 구현한 pooling 모듈에서는 input feature size가 (4, 4)인 경우에는 FSM 구조를 조금 다르게 설계해야 했습니다. 잠시 후에 말씀드리겠지만, FPGA에 코드를 올리기 시작하면 디버깅 과정이 훨씬 힘들어지고, 한 번 synthesize하는 데 소요되는 시간때문에 오래 걸립니다. 따라서 시뮬레이션을 통해 잡아낼 수 있는 오류는 최대한 빨리 잡아내고 시작하는 것이 좋습니다. Python 등을 활용하면 숫자를 이진수로 표현하는 등 연산을 진행 가능한데요, 이러한 툴들의 도움을 받아 다양한 테스트 케이스를 만들어 디버깅에 사용하시길 바랍니다.
- AXI protocol 주의하기 – 별도의 testbench 작성 추천
프로젝트에서는 AXI라는 protocol을 이용하여 모듈 간 소통을 진행해야 할 때가 있습니다. 쉬운 설명을 위해 예를 들어보겠습니다. ‘데이터를 주고, 연산 결과를 받는 모듈 A’와 ‘데이터를 받아 계산하고 그 결과를 A에게 돌려주는 B’ 모듈이 있습니다. 이때, 데이터를 넘겨주기 전에는 ‘A가 넘겨줄 데이터가 준비되었음’과 ‘B는 받을 준비가 되었음’을 서로 확인한 이후에 교환하고, 계산을 진행하고 결과를 보낼 때도 ‘B는 계산을 끝냈고 보낼 준비가 되었음’과 ‘A도 결과를 받을 준비가 되었음’을 서로 확인하게 됩니다. 말로 하면 당연한 것도 같지만, 한 쪽이 준비가 되지 않았는데 반대쪽이 강제로 데이터를 보내는 코드를 작성하는 것이 생각보다 쉽습니다. 이는 시뮬레이션 단계에서는 보통 문제가 되지 않는데, FPGA에 올린 순간부터 발생하는 ‘이유를 파악하기 힘든’ 문제 원인 중 80% 이상을 차지합니다. 이를 미리 확인하기 위해, 강제로 준비 신호를 올렸다 내렸다 하는 매우 간단한 testbench 코드를 별도로 작성하여 실험해보시는 것을 추천드립니다.
- “ILA를 기억해주세요”
ILA란, ‘Integrated Logic Analyzer’의 약자로, 사용법은 구글에 검색해보시면 됩니다. 시뮬레이션 단계에서 Verilog 디버깅을 진행할 때는, 모든 신호들이 변하는 것을 한 눈에 볼 수가 있는데요, 이를 FPGA에 올리게 되면 컴퓨터를 이용하여 확인할 수 있는 것은 최종적으로 출력되는 결과 뿐입니다. 어떤 문제가 발생했는지 알아보려면 설계한 모듈의 논리적인 구조를 계속 생각해보며 수정하거나, 오탈자를 발견하는 것입니다. 이때, ILA를 사용하면 FPGA에서 발생하는 신호의 일부(미리 지정) 캡쳐하여, 특정 trigger의 발생 시점을 주변으로 신호의 파형을 모니터에서 관찰할 수 있습니다. 디버깅 시간을 매우 단축시켜주는 좋은 툴이기에, 사용하시는 것을 강력히 권장드립니다.
3. 진로 선택에 도움되는 점
디지털 시스템 설계 및 실험은 전기정보공학부 과목 분류 기준 중에서는 ‘컴퓨터’, 흔히 말하는 ‘컴텍’에 해당되지만, 논리회로 설계 분야에도 걸쳐 있다고 봐야 할 것 같습니다. ‘하드웨어 설계’를 진행하는 과목인 만큼, 조금이라도 연관이 있는 전공 분야와 연구실은 많습니다. 컴퓨터 아키텍처와도 직접적인 연관이 있고, 특히 accelerator 설계를 연구 주제로 다루는 연구실 진학을 희망한다면 사실상 필수적인 과목이라고 생각합니다.
컴퓨터 시스템 이상 level의 ‘컴텍’을 희망하시는 분들께는 사실 필수라 생각하지는 않지만, 그래도 하드웨어, 특히 accelerator가 어떤 식으로 계산을 빠르게 진행하는 것인지 이해해보는 관점에서는 큰 도움이 되는 수업이라고 생각합니다.
4. 맺음말
디지털 시스템 설계 및 실험은 직접 설계한 accelerator를 FPGA에 올려, CNN의 forward pass를 매우 빠르게! 진행해보는 것을 최종 목표로 하는 과목입니다. 프로젝트 진행 과정은 다사다난했지만, 그 과정에서 정말 많이 생각해보고, 배워나갈 수 있는 과목이라고 생각합니다. 수강하시면 특정 동작을 할 수 있는 하드웨어를 설계하여, 실제로 동작하는 것을 볼 수 있는 신기한 경험을 해보실 수 있습니다. 프로젝트를 진행할 때는 꼭 ILA를 기억해 주시고요, 힘내시길 바랍니다!
[자료 출처 및 참고자료]
(1) 수업 강의자료(이진호 교수님, AISys Lab)
(2) Digital System Designs and Practices(Using Verilog HDL and FPGAs), Ming-Bo Lin, 2008
(3) Verilog Coding Guide, 한규승(인용 조건으로 원본 pdf를 첨부합니다)
(4) (4) EBICS News, accessed 2024.05.22., https://ebics.net/fpga-important-resources-clb-slice-lut-introduction/

'전공백서 > 전기정보공학부' 카테고리의 다른 글
| 전기정보공학부: 알고리즘의 기초 (0) | 2024.06.29 |
|---|---|
| 전기정보공학부: 딥러닝의 기초 (1) | 2024.06.26 |
| 전기정보공학부: 기초회로이론 및 실험 (0) | 2024.06.23 |
| 전기정보공학부: 데이터통신망의 기초 (3) | 2024.02.29 |
| 전기정보공학부: 논리설계 및 실험 (3) | 2023.12.28 |




댓글