
딥러닝을 활용하여 입술 모양을 단어로 추측하기
안녕하세요, 딥러닝을 활용하여 입술 모양을 단어로 추측하는 연구, 일명 Lipreading이라는 분야에 대해 소개해드릴 STEM 12.5기 박인범입니다.
우선 Lipreading의 정의에 대해서 설명해드린 후, Lipreading에 대한 논문들 사이에서 가장 많이 쓰이는 dataset 중 하나인 Lip reading in the wild, 그리고 그 논문들 중 하나인 Ma et al.의 논문에서 어떤 네트워크를 이용하여 lipreading 연구를 진행했는지 살펴보도록 하겠습니다.
Lipreading
Lipreading이란 사람이 연설, 대화와 같이 자연스럽게 말을 하는 상황속에서 입모양의 시간적 변화를 모두 포함하는 프레임을 인풋으로 모델에 넣고, 그 사람이 어떤 단어를 말하고 있는지 알아맞히는 것입니다. 이 글에서는 음성정보 없이 영상데이터만을 이용하는 lipreading에 대해 설명드리고자 합니다. 즉, lipreading에 사용되는 모델은 오직 이미지 정보만 활용해서 화자가 말하는 단어가 무엇인지 추론을 하게 됩니다.
LRW
Ma et al. [3]의 논문을 비롯한 많은 연구에서 학습과 검증에 사용한 데이터셋으로 Lip Reading in the Wild [1], 줄여서 LRW dataset을 채택했습니다.
LRW는 영국 BBC의 토크쇼나 뉴스로부터 천 명이 넘는 화자들의 영상에서 학습과 검증에 사용될 500가지 단어를 선정해서 해당 단어에 대한 영상 클립을 추출하여 만들어졌습니다[1].

500개의 단어는 각 클래스를 대표하며 한 클래스에 대해 800개의 training set, 40개의 validation set과 40개의 test set이 존재합니다. 이 LRW dataset은 연구로 사용되기 위해 다양한 전처리 방법을 도입할 수 있는데요, 가장 먼저 시도됐던 방법은 Martinez et al. [4]의 연구에서 확인하실 수 있습니다.
Towards Practical Lipreading…
Ma et al의 연구에서는 데이터 전처리를 위해 다음과 같은 방법을 사용하였습니다. 대략적인 개요는 아래의 그림[3]에서 보실 수 있습니다.

우선, 영상 정보로부터 68개의 facial landmark를 추출한 후 입술의 좌표를 나타내는 점들을 찍었습니다. 이것을 기반으로 image warping을 하고 입술 선이 수평선과 일치하도록 정렬하였습니다. 마지막으로는 입술 좌표 주변의 96x96 크기로 이미지를 자름으로써 모델에 들어갈 인풋이 완성됩니다.
Overview
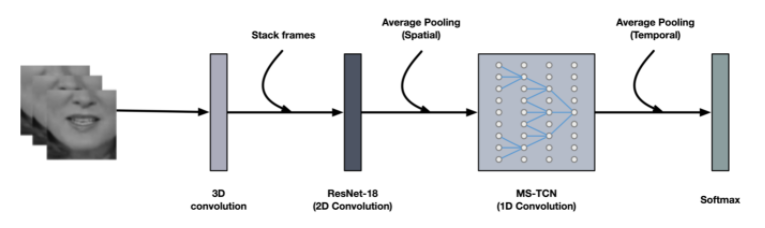
모델의 기본적인 구성은 위의 사진[3]과 같습니다. 데이터 전처리된 인풋이 image flip과 같은 일부 data augmentation을 거친 후 3D CNN, ResNet-18 [5], MS-TCN [2]을 순서대로 거쳐 최종적으로 softmax 후에 나온 단어별로 확률을 알 수 있는 tensor를 아웃풋으로 내보냅니다.
MS-TCN
모델을 구성하는 ResNet-18은 딥러닝의 비쥬얼 정보를 컴퓨팅하는 데에 많이 사용되기 때문에 익숙하실 수 있겠지만 MS-TCN 모델은 낯설 수 있기 때문에 이 네트워크가 전체 흐름에서 어떤 역할을 하는지에 대해 살펴보려 합니다[2].
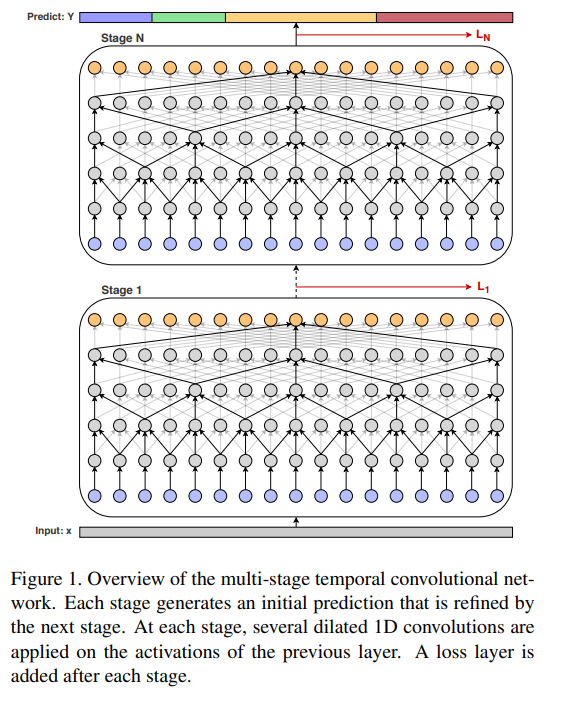
MS-TCN이라는 모델은 Multi-Stage Temporal Convolutional Network의 줄임말입니다. 이 네트워크는 temporal convolution이라고 불리는 TCN을 쌓아서 이전 TCN의 아웃풋이 다음 TCN의 인풋으로 주어지도록 구성되어 있습니다. MS-TCN의 강점은 time 디멘션에 대해 class label을 추측할 때 generalized context를 잘 읽을 수 있도록 한다는 점입니다. 이러한 점은 sequential modeling problem을 다룰 때 RNN보다 유리하다는 것이 밝혀졌습니다.
위와 같은 방식으로 ResNet과 MS-TCN을 적절히 활용하여 입술 모양의 visual information과 프레임 간의 연관성을 time dimension에 대해 파악하여 논문에서 좋은 결과를 낸 것을 확인할 수 있었습니다. 하지만 더 효율적인 data preprocessing 및 data augmentation 방식과 action segmentation에 좋은 backbone들을 활용한다면 lipreading에 있어 더 좋은 성능을 볼 수 있을 것으로 기대됩니다.
References
[1] J. S. Chung and A. Zisserman. Lip reading in the wild. Asian Conf. on Computer Vision, 2016.
[2] Y. A. Farha and J. Gall. MS-TCN: Multi-Stage Temporal Convolutional Network for Action Segmentation. Conference on Computer Vision and Pattern Recognition, 2019.
[3] P. Ma, B. Martinez, S. Petridis, and M. Pantic. Towards Practical Lipreading with Distilled and Efficient Models. IEEE International Conference on Acoustics, Speech and Signal Processing, 2020.
[4] B. Martinez, P. Ma, S. Petridis, and M. Pantic. Lipreading using temporal convolutional networks. IEEE International Conference on Acoustics, Speech and Signal Processing, 2020.
[5] K. He, X. Zhang, S. Ren, J. Sun. Deep Residual Learning for Image Recognition. Conference on Computer Vision and Pattern Recognition, 2015.
[6] https://github.com/mpc001/Lipreading_using_Temporal_Convolutional_Networks
'STEM - 학술세미나 > 컴퓨터공학' 카테고리의 다른 글
| 3D 렌더링에 인공지능을 어떻게 사용할까? (2) | 2022.04.12 |
|---|---|
| 딥러닝 모델의 정확도 올리기 (6) | 2022.02.18 |
| YoLO로 객체 인식하기 (2) | 2021.12.31 |
| Invertible Adversarial Attack (1) | 2021.10.31 |
| Range Minimum Query를 통해 살펴보는 컴퓨터 알고리즘 (0) | 2021.10.16 |




댓글