
YoLO로 객체 인식하기
안녕하십니까? YoLO 신경망을 통한 객체 인식에 대해 함께 알아볼 공우 12기 AI매니아입니다.
우선 YoLO가 잘하는 것은 객체 인식입니다. 그래서 객체 인식이 무엇인지에 대해 알아보고, 이것이 어디에 활용되는지 먼저 말씀드리도록 하겠습니다. 그리고 나서 YoLO의 원리에 대해서 CNN이 무엇인지, 전체적인 신경망 구조가 어떻게 되는지에 대해서 알아보도록 하겠습니다.
객체 인식이란?
이 YoLO라는 신경망은 객체 인식이라는 문제를 해결하기 위해 만들어졌습니다.
여기서 객체 인식이란, 딥러닝 또는 머신 러닝을 통해서 이미지 또는 영상의 객체를 식별해 내는 것을 의미합니다.
컴퓨터비전에 이와 유사한 문제로 객체 탐지도 있는데, 객체 탐지는 해당 객체가 있는지 없는지만 판별해 주는 데에 반해, 객체 인식은 바운딩 박스를 통해 해당 객체가 어디에 있는지까지 판별한다는 차이점이 있다고 할 수 있습니다.

YoLO와 객체 인식의 활용
그렇다면 YoLO를 알면 좋은 점, YoLO의 응용 분야에 대해서 말씀드리도록 하겠습니다.
우선 YoLO는 You only Look Once의 약자로, 사람이 사진이나 풍경을 보고 내가 관심있는 물체가 어디어디에 있는지를 단번에 파악해 내는 것처럼 빠르게 물체들을 캐치해 내는 데에 목적이 있습니다.
따라서 이러한 능력이 필요한 여러 기술 분야에 응용할 수 있는데요, 대표적인 분야가 테슬라로 유명한 자율주행 분야입니다.
운전자는 운전을 하면서 빠르게 앞에 사람이 지나가는지, 차는 어디에 있는지를 파악해 낼 수 있습니다. 따라서 이 역할을 AI가 대신하기 위해서는 빠르고 정확하게 내가 관심이 있는 대상이 어디에 있는지를 잘 파악하고 피해갈 수 있어야 합니다. 따라서 YoLO는 자율주행이 탑재된 시스템에서 단골로 등장하는 개념이라고 할 수 있습니다.
자율주행 외에도 컴퓨터비전을 통한 정확하고 빠른 판단이 필요한 사물인식 임베디드 시스템에서도 활용됩니다.
대표적으로 스마트팜에도 YoLO가 활용될 수 있습니다. 농부가 일일히 열매들의 상태를 확인하러 다니는 것이 번거로울 수 있기 때문에, 익은 열매가 어디 있고, 덜익은 열매가 어디에 있는지 물을 주어야 하는 식물이 어디에 있는지를 YoLO를 통해서 판별해 낼 수도 있습니다.
CNN이란?
그렇다면 이러한 비전 Task를 수행하는 YoLO 신경망의 기본적인 원리라고도 할 수 있는 CNN에 대해서 알아보도록 하겠습니다.
원래 기본적인 신경망은 벡터 to 벡터 매핑을 해주는 MLP입니다. 그래서 실제로 MLP를 이용하여 이미지를 처리하는 것도 가능합니다. 그런데, 이런 식으로 처리를 하면 이미지를 1차원으로 변환하여 처리를 하게 되기 때문에, 상하 인접한 픽셀 값이 매우 멀리 떨어져 버리게 됩니다. 이렇게 이미지의 공간적 지역적 정보를 활용하지 못하는 한계점을 극복하고자 나온 것이 바로 CNN 입니다.
CNN에서는 이미지를 1차원으로 펴서 처리를 진행하는 것이 아니라, 커널이라고 하는 필터가 이미지를 돌아다니면서 공간적인 정보를 수집하게 됩니다.
CNN은 네 개의 Layer로 구성이 되는데, Convolutional Layer, Pooling layer, Activation layer, Fully connected-layer 로 이루어져 있습니다.
Convolutional layer은 이미지를 이러한 필터에 통과시키는 층입니다.
이 예시에서는 3 x 3 필터가 5 x 5 이미지 위를 돌아다니면서 내적한 값들로 3 x 3 이미지를 만들어서 다음 층으로 보내주게 됩니다. CNN이 학습하는 변수들은 이 필터에 적힌 값들인데, 이 값들을 잘 설정해야 이미지의 특징을 잘 뽑아내서 다음 층으로 전달할 수가 있기 때문에, 학습을 진행하면서 이러한 필터 값을 최적화시키게 됩니다.
Pooling Layer은 큰 사이즈의 이미지에서 특징적인 부분을 더 선명하게 추출하기 위해서 dimension을 줄이는 층입니다. 흔히 Max Pooling 기법과 Average Pooling을 사용하는데, Max Pooling은 이렇게 단위별로 가장 큰 값만을 추려 내는 기법이고, Average Pooling은 이렇게 단위별로 값들을 평균 내서 추려 내는 기법입니다.
그래서 Conv, Pool 과정, 그리고 활성화함수를 통과하는 과정을 여러 번 거친 뒤, MLP에 통과시키는 과정을 거쳐 이미지의 특성을 판별하게 됩니다.


YoLO의 신경망 구조
그래서 이를 바탕으로 YoLO 신경망의 구조에 대해 알아보도록 하겠습니다.
우선 인풋으로는 448 x 448 이미지가 들어오고 그 뒤에 계속해서 Conv Layer과 Max Pooling Layer을 계속 거치게 됩니다. 그래서 활성화함수도 통과하고 쭉쭉 가다가, FC layer을 거쳐서 최종적으로 7 x 7 x 30 텐서로 가게 됩니다.
그래서 이 텐서 결과값들을 가지고 여러 확률론적 계산을 하여, 가장 유력한 물체를 찾고 바운딩박스를 그리게 되는 것입니다.

성능 비교 지표
다음은 객체인식 네트워크를 비교하는 지표입니다.
좋은 네트워크가 되기 위해서는 두 가지를 잘하면 됩니다. 빠르게 인식할 수 있어야 하고, 정확하게 인식할 수 있어야 합니다. 이 두가지에 대한 성능 지표가 각각 FPS와 mAP입니다.
FPS는 Frame Per Second 의 약자로, 이 객체인식 네트워크가 1초에 몇 장의 이미지를 인식할 수 있는지에 대한 수치입니다. 이러한 수치가 높을수록 빠른 인식이 필요한 자율주행 등에 유리한 네트워크라고 볼 수 있습니다.
다음 mAP는 mean Average Precision의 약자로, 쉽게 말하면 정확도가 100점 만점에 몇점인지를 뜻합니다. Average Precision은 특정 사물에 대해서 아래와 같이 예측치 바운딩 박스와 실제 바운딩 박스 사이의 합집합에 대한 교집합의 비율값들을 기반으로 계산하고, 이를 모든 사물들에 대해서 평균낸 값이 mAP가 됩니다.

YoLO와 다른 네트워크와의 비교
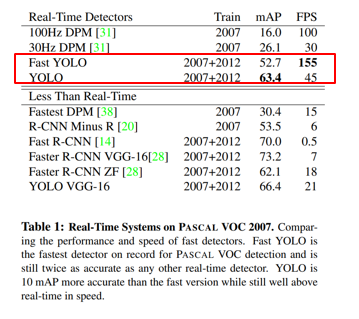
이제 YoLO의 성능수치를 살펴보도록 하겠습니다.
YoLO 논문에서는 이를 경량화시킨 Fast YoLO, 그리고 다른 네트워크들의 성능수치를 제시합니다.
표를 보시면 Fast YoLO가 YoLO보다 정확도는 낮지만, 경량화된 모델을 사용해서 훨씬 빠르게 인식을 한다는 것을 알 수 있습니다. 일반적으로 모델의 규모와 정확도 사이에는 트레이드오프 관계가 있으며, 응용시키는 상황에 맞게 적합한 네트워크를 선택해야 합니다. 빠른 인식이 중요하면 Fast YoLO, 느리더라도 정확한 인식이 중요하면 그냥 YoLO를 사용하면 됩니다.
그래서 이렇게 인식 속도와 정확도 간의 Trade off 관계가 존재하고 이후의 많은 객체인식에서도 경량화된 버전을 같이 만들어 적재적소에 원하는 신경망을 선택할 수 있도록 합니다.
이미지 출처
[그림 1] <You Only Look Once: Unified, Real-Time Object Detection> Joseph Redmon 외. (2016)
[그림 2] https://halfundecided.medium.com/딥러닝-머신러닝-cnn-convolutional-neural-networks-쉽게-이해하기-836869f88375
[그림 3] <You Only Look Once: Unified, Real-Time Object Detection> Joseph Redmon 외. (2016)
[그림 4] https://jonathan-hui.medium.com/map-mean-average-precision-for-object-detection-45c121a31173
[그림 5] <You Only Look Once: Unified, Real-Time Object Detection> Joseph Redmon 외. (2016)
'STEM - 학술세미나 > 컴퓨터공학' 카테고리의 다른 글
| 딥러닝 모델의 정확도 올리기 (4) | 2022.02.18 |
|---|---|
| 딥러닝을 활용하여 입술 모양을 단어로 추측하기 (2) | 2022.02.08 |
| Invertible Adversarial Attack (1) | 2021.10.31 |
| Range Minimum Query를 통해 살펴보는 컴퓨터 알고리즘 (0) | 2021.10.16 |
| VR 기기의 현재와 미래 (0) | 2021.06.01 |




댓글