
안녕하세요?
저는 STEM 11.5기 활동 중인 이태균이라고 합니다. 이 글을 읽고 계신 여러분, 혹시 알고리즘에 대해 들어보셨나요? 알고리즘이라는 단어는 일상생활에 굉장히 많이 사용됩니다. 예를 들어서, 제가 즐겨보는 유튜브만 해도 '유튜브 알고리즘'이 영상을 추천하곤 합니다. 하지만 오늘 소개할 알고리즘은 조금 더 좁은 개념의 알고리즘 일 것 같습니다. 사전에 검색해보니, "문제풀이에 필요한 계산절차 또는 처리과정의 순서를 뜻함." 이라고 나와있네요!
오늘 소개할 알고리즘은 컴퓨터 알고리즘, 그 중에서도 RMQ(Range Maximum Query)라는 특정한 문제를 푸는 알고리즘들을 소개해볼까 합니다. 맨 처음에는 초등학생들도 떠올릴 수 있는 직관적인 알고리즘부터, 마지막에는 열심히 이해하려고 노력하지 않으면 이해하기 힘든 알고리즘까지 한 번 이야기 해보겠습니다. 그럼, 한 번 천천히 소개해보도록 하겠습니다!
배경지식으로 알아야 할 것
Big O notation
저희가 배경지식으로 꼭 알아야 할 내용이 한 가지 있습니다. 바로 Big O notation인데요, 컴퓨터나 응용수학 관련 연구에서 식의 scale을 나타낼 때 꼭 사용해야하는 개념입니다. 엄밀히 정의를 하기보다는 예시를 들어서 설명하겠습니다.
$$f(n) = n^2 + 4n + \log{n} + \sqrt{n} + 6$$
이라는 식이 있다고 합시다. 이 커짐에 따라 어떤 항이 의 크기를 결정하게 될까요? 항 별로 따로 떼어내서 살펴보겠습니다.
우선, 가장 오른쪽의 상수항은
일 때도 , 일 때도 , 일 때도 입니다.오른쪽에서 두 번째에 있는 항은
일 때는 , 일 때는 , 일 때는 입니다.반면 가장 왼쪽에 있는 항은
일 때는 , 일 때는 , 일 때는 입니다. 항의 증가 속도가 매우 빠르다는 것을 확연하게 비교해볼 수 있습니다.눈치 채셨는지 모르겠지만, 식 은 항이 빠르게 커지는 순서대로 내림차순으로 정렬되어 있는 상태입니다. 위와 같은 식의 경우에, 매우 큰 상수 에 대하여 의 크기를 결정짓는 항은 바로 항 입니다. 이는 차수를 살펴보면 쉽게 이해할 수 있습니다.
이 때 저희는이라고 나타내기로 약속하게 됩니다. 이 방법을 Big O notation이라고 부릅니다.
시간복잡도
특히, 알고리즘의 시간복잡도를 구할 때 위와 같이 input의 크기를 으로 두고 Big O notation을 통해서 얼마나 좋은 알고리즘인지를 표현하게 됩니다. 시간복잡도란, 알고리즘이 돌아가는 데 걸리는 시간을 Big O notation으로 표현한 것입니다.
일반적으로 CPU는 1억(100,000,000)번의 연산을 하는데 약 1초가 걸립니다. 물론, 요즘은 기술이 발전해서 조금 더 많은 연산을 한다고 알려져 있는데, 통상적인 수치대로 1억번 연산을 한다고 대략적으로 생각해보겠습니다.
만약 어떤 문제를 1초 안에 풀고 싶을 때, 문제를 해결할 알고리즘이
이라면 개짜리 input, 이라면 개의 input, 이라면 개의 input, 이라면 개의 input을 넣을 수 있습니다. 즉, 알고리즘의 시간복잡도를 줄이는 것은 곧 같은 시간동안 얼마나 큰 input을 처리할 수 있는가와 직결됩니다.따라서 알고리즘의 시간복잡도를 줄이는 것은 매우 중요한 과제 중 하나입니다.
공간복잡도
알고리즘의 공간복잡도라는 개념도 있습니다! 공간복잡도는 알고리즘을 돌릴 때 차지하는 최대 공간의 양을 Big O notation으로 표현한 것입니다. 컴퓨터 알고리즘이 차지하는 공간 또한 적으면 적을수록 유리하겠죠? 따라서 앞으로 소개할 모든 알고리즘에서 시간복잡도와 공간복잡도를 구하여 비교할 것입니다.
Range Minimum Query 란?
숫자가개 있는 배열이 하나 있고, 해결해야 하는 의 쿼리가 개 들어오는 상황을 생각해 봅시다. 이 때 각 쿼리에서 주어진 구간을 입력으로 주면, 그 구간의 최솟값을 출력으로 구하면 되는 문제입니다. 예시 그림을 보면 훨씬 이해가 쉬울 것입니다.

위 그림을 보시면,
첫 번째 쿼리로 가 들어왔는데요, 2~4번째 칸 각각에 들어있는 값을 확인해보시면 4, 5, 1임을 확인할 수 있고, 이 중 최솟값은 이 됩니다.
두 번째 쿼리로는 가 들어왔는데요, 0~3번째 칸 각각에 들어있는 값을 확인해보시면 4, 3, 4, 5임을 확인할 수 있고, 이 중 최솟값은 이 됩니다.
세 번째 쿼리로는 가 들어왔는데요, 0~7번째 칸 각각에 들어있는 값을 확인해보시면 4, 3, 4, 5,1,7,2,9임을 확인할 수 있고, 이 중 최솟값은 이 됩니다.
이제 어떤 종류의 문제인지 아시겠죠? 이해가 그다지 어렵지 않은 직관적인 문제입니다.
자, 그렇다면 본격적으로 이 문제를 푸는 알고리즘을 하나씩 소개해보도록 하겠습니다.

우선, 소개하기 전에 앞으로 그림 우상단에 표기할 다섯가지 특징들을 적어보겠습니다.
첫 번째로 알고리즘의 난이도입니다. 그야말로 얼마나 이해하기 어려운지에 대한 내용입니다. 가급적 쉬운 난이도부터 어려운 난이도 순으로 배치하겠습니다. 물론 제 개인적인 의견 100%입니다.
두 번째로 알고리즘의 중요도입니다. 이거야말로 정말 개인적인 의견인데, 학문적인 중요도를 표시해보았습니다. 자주 사용되고 범용적으로 사용되는 알고리즘일수록 점수가 높습니다.
세 번째로 전처리하는 데 걸리는 시간입니다. 알고리즘을 본격적으로 가동시키기 전에 전처리에 필요한 시간복잡도를 의미합니다.
네 번째로 업데이트하는 데 걸리는 시간입니다. RMQ 문제에서 배열의 값이 중간중간 바뀔 수 있다고 생각했을 때, 이 값을 바꾸는 데 걸리는 시간입니다.
다섯 번째로 쿼리 당 걸리는 시간입니다. 들어오는 쿼리마다 출력값을 도출하는 데 걸리는 시간입니다.
1. Brute Force
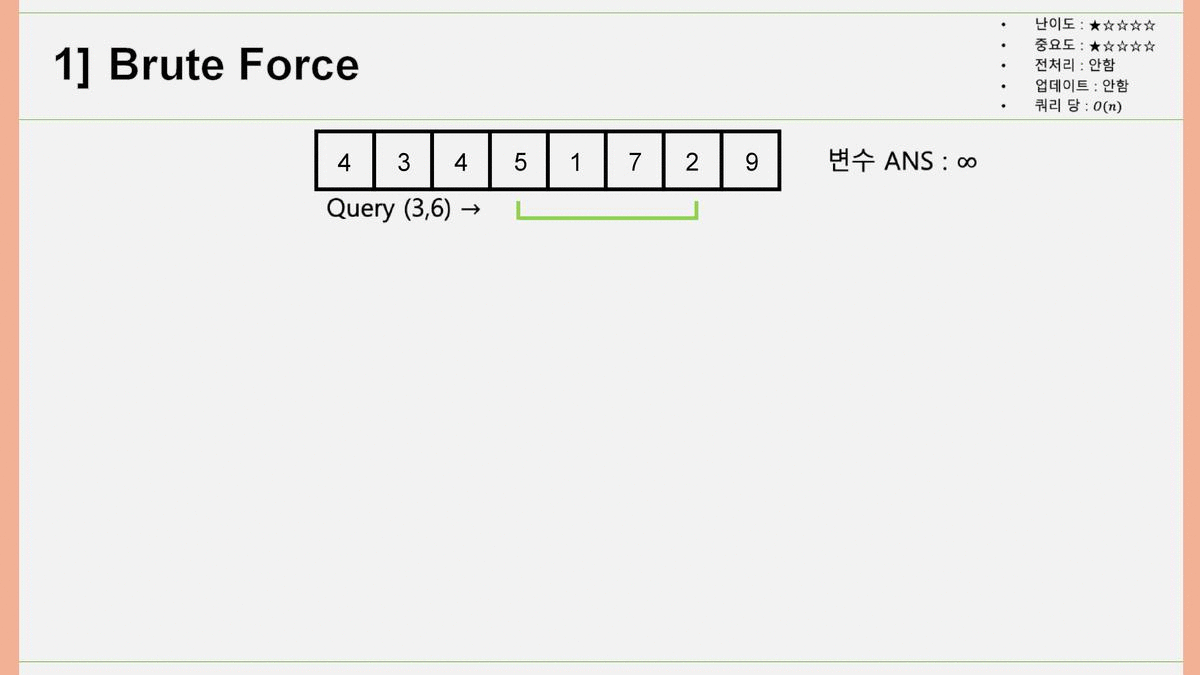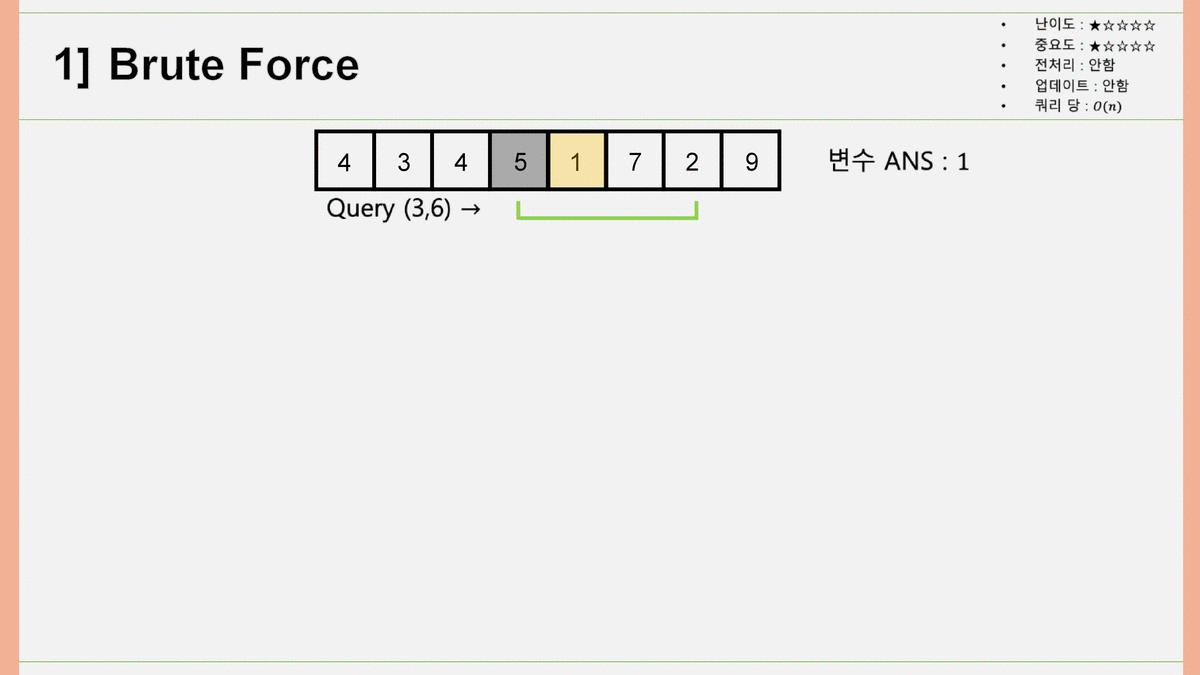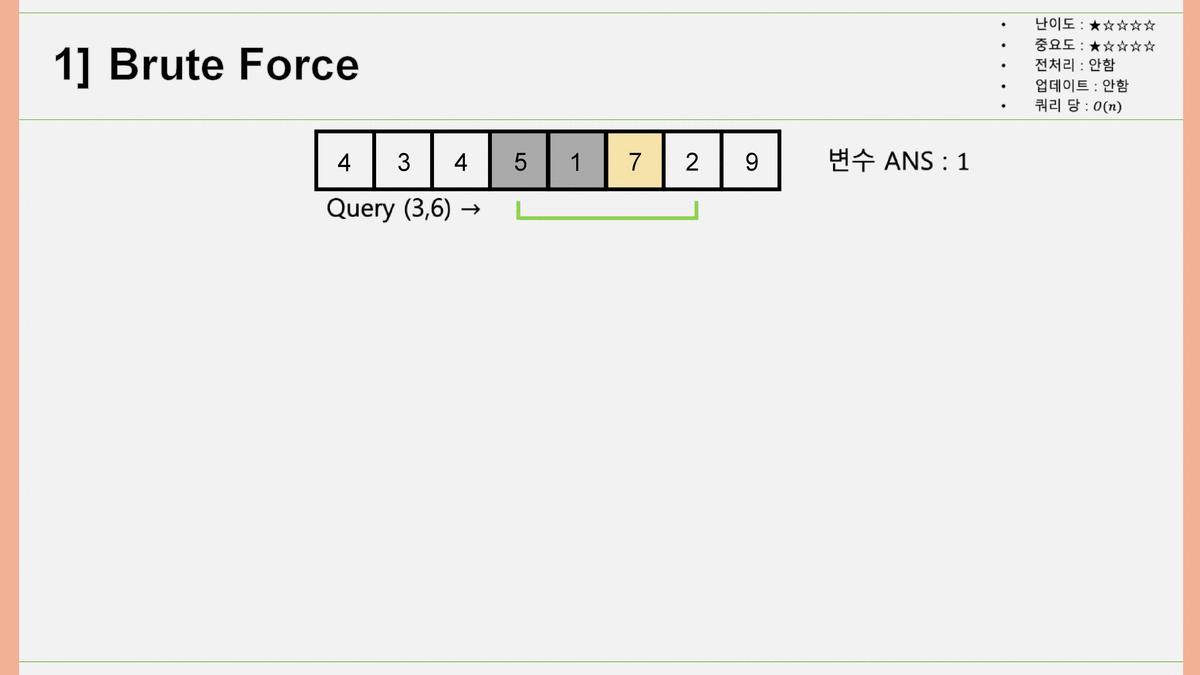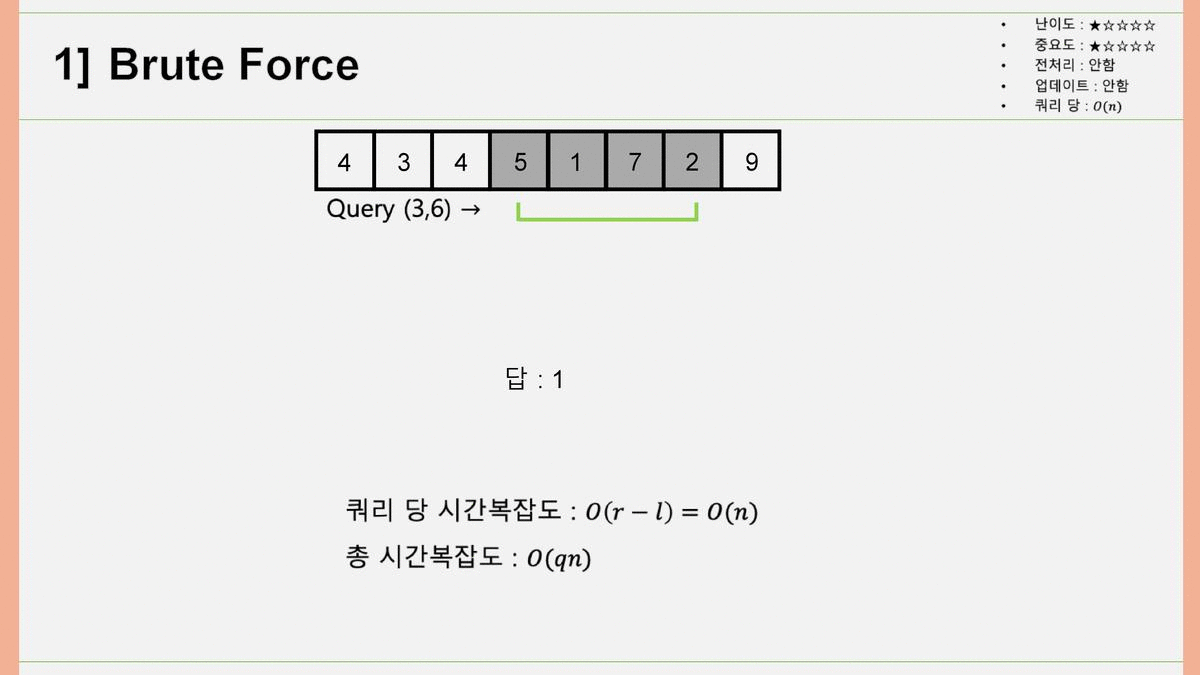
Brute Force, 한국어로 노가다. 위 과정을 생각해내는 건 매우 직관적이고 쉽습니다. 처음이니까 풀어서 설명하자면, 쿼리 에 대해 최솟값을 구할 때, 배열의 3번째, 4번째, 5번째, 6번째 원소에 각각 접근하여 값을 얻어내어 그 동안의 최솟값(변수 ANS)와 비교한 뒤, ANS보다 배열의 원소 값이 작은 경우 ANS 값을 갱신합니다. 이렇게 계산할 경우, 쿼리 당 시간복잡도는 이 되고, 쿼리가 개 있으므로 총 시간복잡도는 이 됩니다. 이 값이 앞으로 나올 모든 시간 복잡도 중 값이 가장 큽니다. 결국, 이 걸리는 시간을 줄이는 것이 우리의 목표가 되겠습니다.
하지만 이 Brute Force 방법에는 직관적이고 쉽다는 것 외에도 장점이 한 가지 더 있습니다. 그건 바로.. 배열의 값을 업데이트하는 것이 매우 자유롭다는 것입니다. 배열의 값을 중간에 업데이트 하든 말든, 그냥 매번 값에 접근하여 쿼리를 처리하면 되기 때문입니다.
2. 미리 전부 전처리

위 사진과 같이, 모든 가능한 쿼리의 순서쌍 에 대해 미리 표를 만들어서 답을 구해둡니다. 미리 기출문제 답을 다 적어두는거랑 비슷합니다. 이 경우에, 전처리가 시간이 걸려서 시간을 많이 잡아먹고, 배열의 값을 하나 바꾸었을 때 전처리 표의 내용을 바꾸는데 이 걸려서 업데이트에 취약합니다(시간이 많이 걸립니다). 하지만, 시간복잡도가 쿼리 당 입니다. 이 작고 가 클 때 매우 효율적일 수 있습니다.
3. Sqrt Decomposition

전처리의 경우 바구니 개에 대해 개의 원소를 더해줘야 하므로 총 걸리는 시간이 입니다. 업데이트에 걸리는 시간은 배열에서 업데이트 하는 원소가 담긴 바구니의 최솟값을 다시 구해줘야 하므로 바구니의 최대 원소 갯수인 만큼의 시간이 걸립니다.
이는 매우 강력한 아이디어입니다. 쿼리 당 걸리는 시간이 꽤 적고, 업데이트가 빠른 시간 내에 가능합니다. 앞의 두 알고리즘에 비하면 비약적인 발전이 있었습니다.
4. Segment Tree
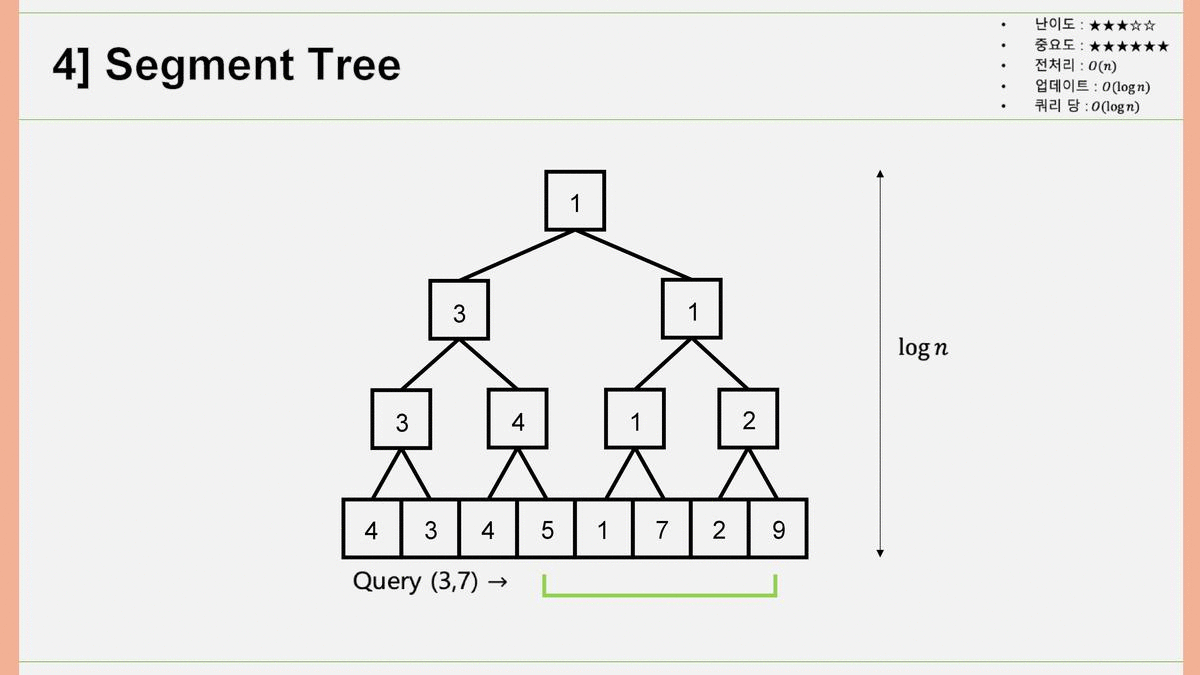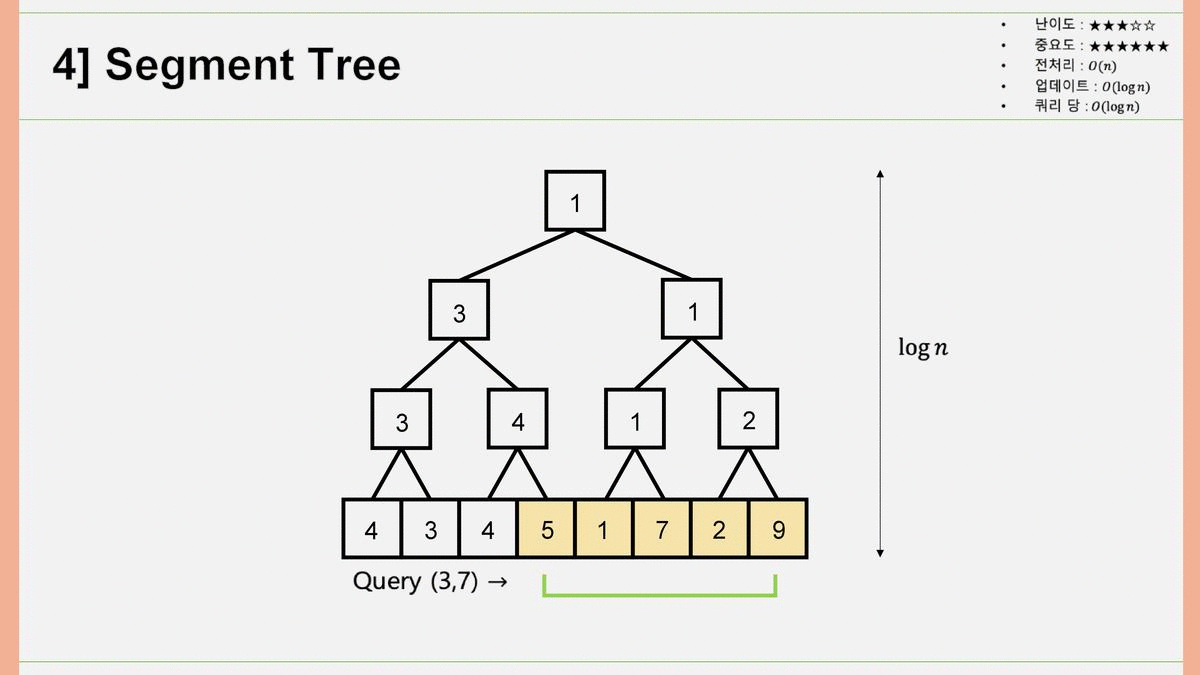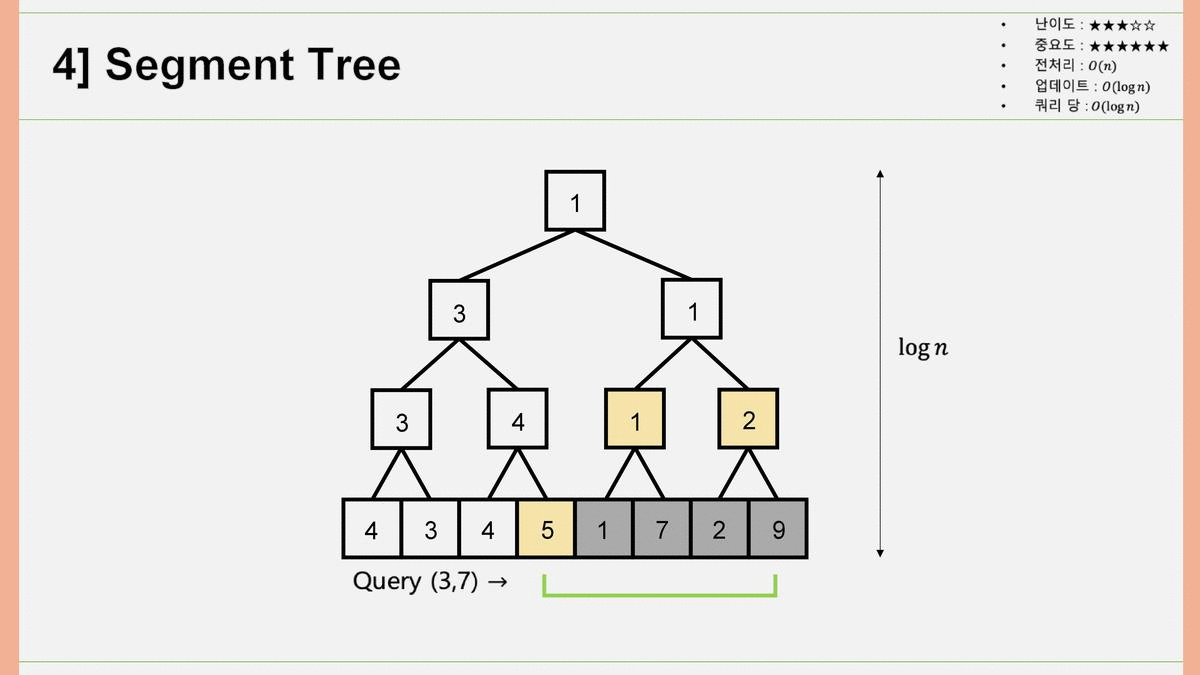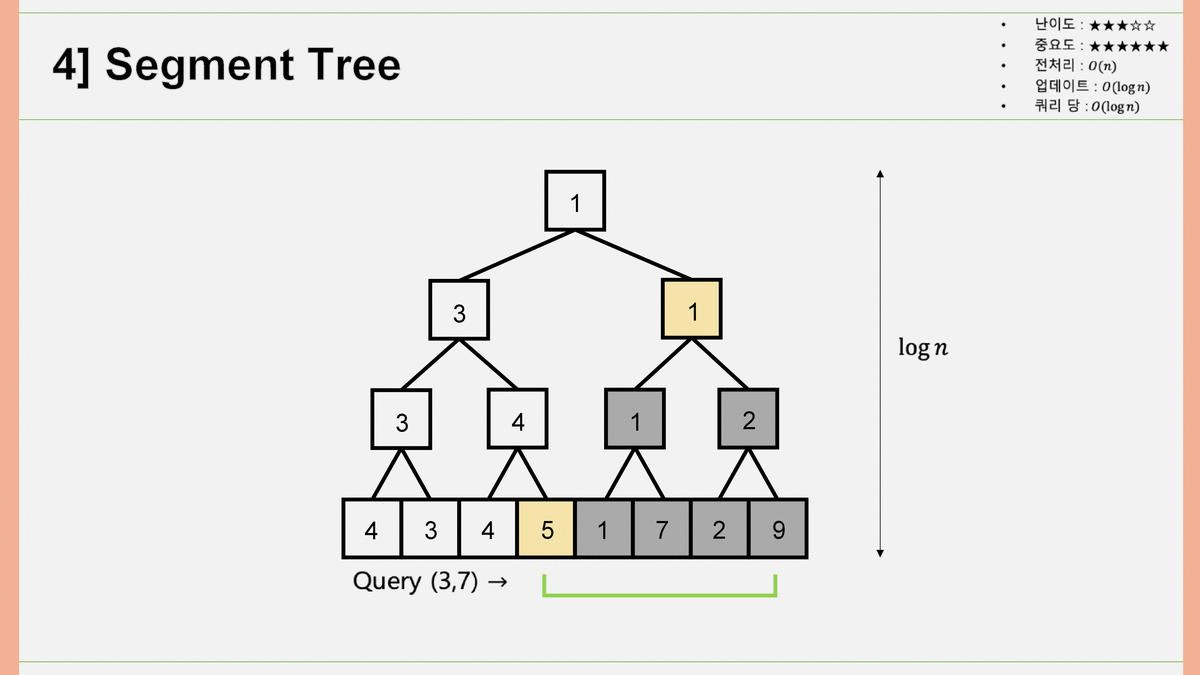
인접한 두 개의 행렬원소를 묶어서 부모 노드를 만들고, 그 부모 노드끼리를 묶어서 부모의 부모 노드를 만들고.. 하는 과정을 통해서 Binary Segment Tree를 구성합니다. 어떤 쿼리가 들어왔을 때, 양끝의 노드가 '부모를 공유하는 다른 자식노드(형제)'를 빼고 쿼리에 들어와 있으면 값을 불러오고, 부모를 공유하는 다른 자식노드와 함께 쿼리에 들어와 있으면 부모노드의 값을 재귀적으로 탐색하여 최솟값을 알아내는 알고리즘입니다. 전처리 과정은 총 개 원소를 채우므로 , 업데이트 과정에서 걸리는 시간은 Segment Tree의 높이만큼 진행되므로 , 쿼리당 걸리는 시간은 마찬가지로 Segment Tree의 높이만큼 진행되므로 가 됩니다.
Segment Tree는 매우매우매우 강력한 알고리즘입니다. 최솟값을 구하는 문제 말고도, 합을 구하거나 최빈값을 구하는 문제 등 다양한 분야에 응용되어 사용될 수 있습니다. 그리고 대부분의 경우 은 충분히 작은 숫자이기 때문에 이 이상이 요구되는 문제가 많지 않습니다.
5. Sparse Table
하지만 이에 만족하지 못한 사람들이 더욱 강력한 알고리즘들을 생각해내기 시작했습니다. 바로 Sparse Tree 입니다.

위 사진처럼 모든 k에 대해 연속적인 길이 의 최솟값을 미리 구해둡니다. 가령, 길이의 최솟값의 경우 배열의 첫 번째 값에 4, 3, 4, 5 의 최솟값인 3, 두 번째 값에 3, 4, 5, 1의 최솟값인 1을 저장해두는 식입니다. 이렇게 미리 값을 전처리 해 둘 경우,
위 사진처럼 쿼리 부분을 덮는 길이의 수열 두 개로 나눌 수 있습니다. 각각의 최솟값을 구해와서 두 수 간의 최솟값을 출력해주면 됩니다.
이렇게 계산을 할 경우 각 쿼리 당 걸리는 시간을 무려 , 즉 상수시간으로 줄일 수 있습니다. 하지만, 문제 풀이 과정에서 라는 성질을 사용했기 때문에, 이 문제에만 국한되는 풀이입니다. 또한, 업데이트가 불가능하다는 단점이 있습니다.
따라서 Segment Tree와 Sparse Table을 비교할 때는 현재 해결하고자 하는 문제에서 요구하는 시간복잡도가 무엇인지를 더 따져봐야합니다.
6. 정신나간 Sparse Table(?)
이제 대망의 알고리즘[1]만 남았습니다. 이 부분은 많이 어려울 수 있습니다.
이 sparse table의 전처리를 에서 으로 줄이는 방법이 있습니다. 그 전에, 우선 알고리즘의 전개 과정에 나오는 LCA(Lowest Common Ancestor) 문제를 먼저 설명드리겠습니다.
LCA(Lowest Common Ancestor)
트리에서 임의의 두 노드를 잡았을 때 두 노드를 모두 포함하는 서브트리의 root 중 가장 작은 것을 찾는 문제입니다.
RMQ를 LCA로 풀 수 있고, LCA를 RMQ로 풀 수 있는데 이 경우에 기존의 RMQ 문제를 LCA로 한 번 바꿨다가 다시 RMQ로 바꿔서 특수한 형태의 RMQ를 풀어서 빠르게 전처리를 하게 됩니다.
무슨 말인지 잘 모르시겠다고요?
다시 원래 문제로 돌아와서,

위 사진처럼 RMQ 문제를 LCA문제로 바꿀 것입니다. 위와 같은 Tree를 Cartesian Tree라고 하는데, 좌에서 우로 순서대로 원소를 보시면 순서가 그대로 유지되고, 각 노드는 0~2개의 자식 노드를 가지며, 왼쪽 자식 노드는 부모 노드보다 작고 오른쪽 자식 노드는 부모 노드보다 크다는 것을 관찰하실 수 있습니다. 이렇게 배열로부터 Cartesian Tree를 구축하는 것은 Stack을 이용하면 의 시간이 걸립니다.

이번엔 다시 LCA문제 Tree를 배열로 바꿔서 RMQ 문제로 만들건데요, Cartesian Tree에 대해 dfs를 진행합니다. 이 때, 거쳐가는 모든 노드를 기록하고(중복 허용), 왼쪽 노드를 오른쪽 노드보다 먼저 거칩니다. 이렇게 진행한 dfs의 Node List를 (깊이, 숫자)로 기록합니다. 그런 뒤에, 깊이만 살펴보겠습니다. 위 예시 같은 경우에, 순서대로 0, 1, 2, 1, 2, 3, 2, 1, 0, 1, 2, 1, 2, 1, 0 인데, 이 배열은 인접한 수끼리 1씩 차이난다는 특징을 확인할 수 있습니다. 또한, 이 배열에서 RMQ 문제를 푸는 것이, Tree에서 LCA 문제를 푸는 것과 동치라는 것을 관찰을 통해 확인할 수 있습니다. 이 새롭게 생성된 RMQ 문제를 RMQ라고 부릅니다.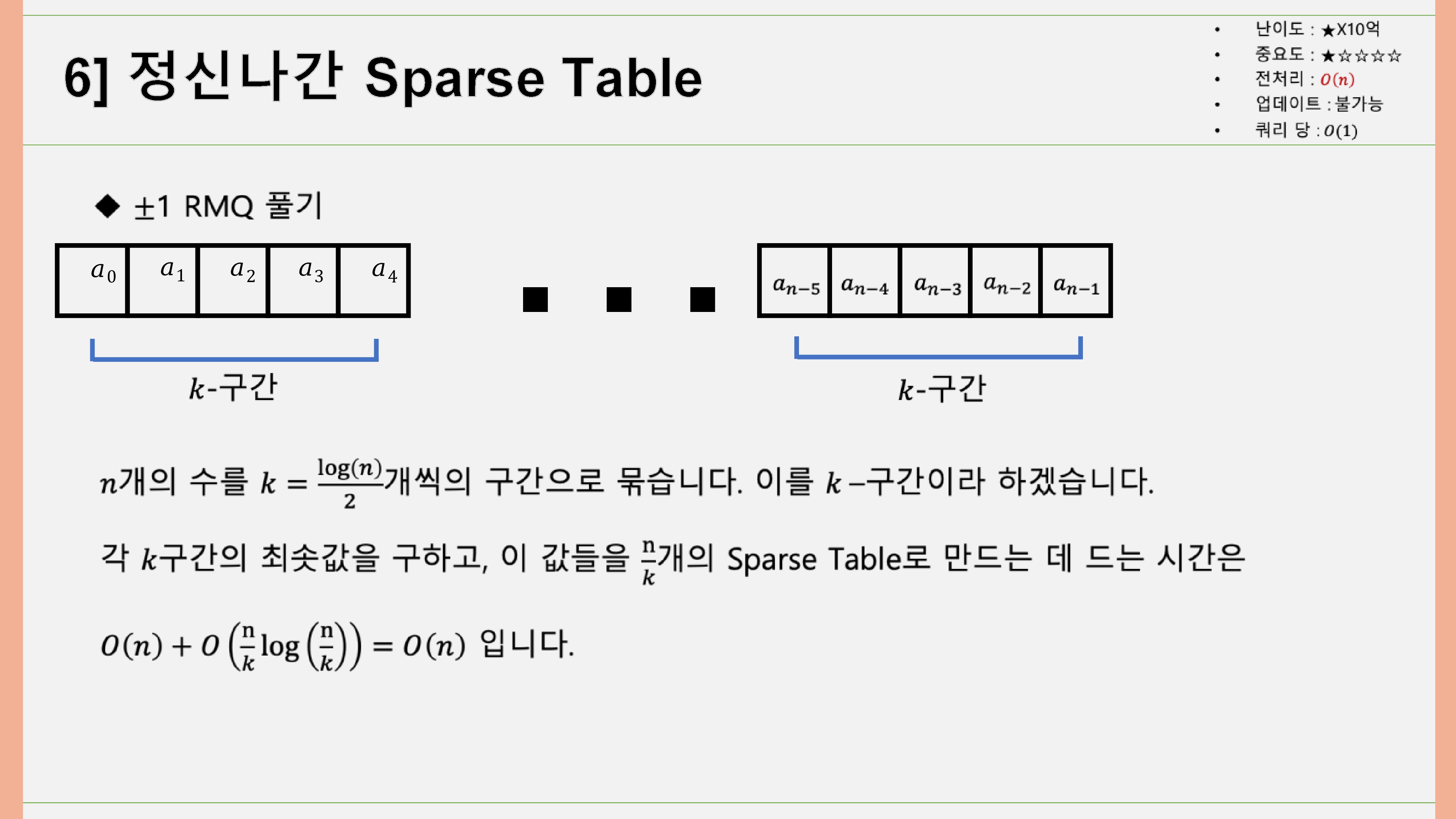
이제 RMQ를 푸는 데 집중할 것입니다. 이 배열은 기존의 n보다 길지만, n의 정수배이므로 RMQ의 길이를 새롭게 n으로 재정의하겠습니다. 이 때, 개의 수를 개씩의 구간으로 묶습니다. 이를 k-구간이라고 하면, 각 k-구간의 최솟값을 구하고, 이 값들을 개의 Sparse Table로 만드는 데 드는 시간은 입니다.
이 때, 양 끝 부분을 제외한 '온전한 바구니'들의 최솟값의 경우 미리 구해둔 Sparse Table로 에 최솟값을 구할 수 있고,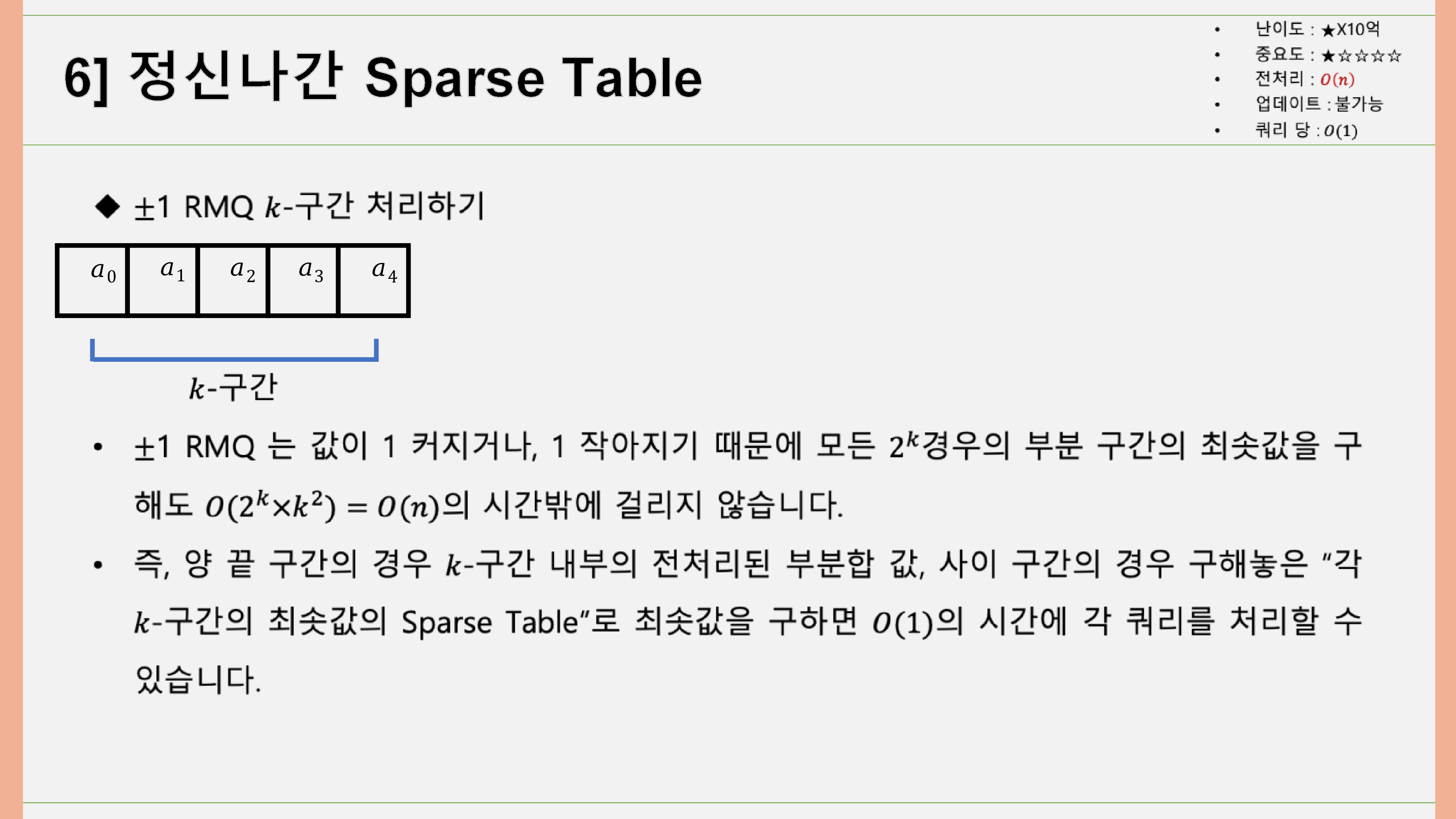
양 끝 부분의 경우에는 RMQ가 값이 1 커지거나, 1 작아지기 때문에 모든 경우의 부분 구간의 최솟값을 구해도 의 시간밖에 걸리지 않습니다. 즉, 양 끝 구간의 경우 k-구간 내부의 전처리된 부분합 값, 사이 구간의 경우 구해놓은 “각 k-구간의 최솟값의 Sparse Table”로 최솟값을 구하면 𝑂(1)의 시간에 각 쿼리를 처리할 수 있습니다.
마치며..
Range Minimum Query 문제를 해결하는 다양한 알고리즘에 대해 알아보았습니다. 끝까지 읽어주셔서 감사합니다!
[1] Bender, Michael A., and Martin Farach-Colton. "The LCA problem revisited." Latin American Symposium on Theoretical Informatics. Springer, Berlin, Heidelberg, 2000.
'STEM - 학술세미나 > 컴퓨터공학' 카테고리의 다른 글
| YoLO로 객체 인식하기 (2) | 2021.12.31 |
|---|---|
| Invertible Adversarial Attack (1) | 2021.10.31 |
| VR 기기의 현재와 미래 (0) | 2021.06.01 |
| 컴퓨터 그래픽스 - 1. 3D물체를 어떻게 표현할까 (0) | 2019.12.11 |
| 컴퓨터 그래픽스 - 0. Introduction (0) | 2019.11.29 |




댓글