
6. Sorting (2)
지난 글에서 살펴본 $\mathcal{O}(n^2)$ 정렬 알고리즘의 경우, $n = 10^5$ 정도만 되어도 오래 걸립니다. 제 컴퓨터에서는 정수 $10$만 개를 정렬하는데 대략 24.5초 정도가 걸렸습니다. 여기서 $n$을 $10$배 하여 데이터가 $100$만 개가 된다면, 정렬이 현실적인 시간 안에 끝나지 않을 것 같습니다. 보다 빠른 알고리즘이 필요할 것 같습니다.
이번 글에서는 지난 글에서 소개한 정렬 알고리즘보다 효율적으로 동작하는 정렬 알고리즘을 2가지 소개하겠습니다.
두 정렬 알고리즘 모두 분할 정복(Divide and Conquer)이라는 굉장히 중요한 알고리즘 디자인 기법을 사용합니다. 이 기법에 대해서는 다른 글에서 더 상세하게 다루도록 하겠습니다.
지난 글과 마찬가지로, 정수 $n$개가 담긴 배열을 오름차순으로 정렬하는 상황을 가정하겠습니다. 추가로 이번 글에서는 $n = 2^k$ ($k$: 정수) 꼴임을 가정합니다. 만약 $2$의 거듭제곱 형태가 아니라면 더미 데이터(예를 들어 데이터에 없는 엄청 큰 수)를 추가하여 $2$의 거듭제곱 형태가 되도록 데이터 크기를 조절할 수 있습니다.
Merge Sort
병합 정렬(Merge Sort)은 주어진 배열을 둘로 나누어 각각을 정렬한 뒤 정렬된 두 배열을 병합(merge)하여 정렬하는 방법입니다.

우선 주어진 배열을 절반으로 나누고, 각각을 재귀적으로 정렬합니다. 그러면 정렬된 두 개의 부분배열 left, right를 얻었으니 이 두 배열을 잘 병합하여 정렬된 배열을 얻으면 될 것입니다. 코드로 살펴보면 다음과 같습니다.
이 때, 병합 과정에서 부분배열 left, right가 정렬되어 있다는 사실을 이용하여 효율적으로 병합해야 합니다. 반대로 이 사실을 이용하지 않는다면 부분배열을 각각 정렬한 의미가 퇴색될 것입니다.
정렬된 두 부분배열을 어떻게 병합하면 좋을까요? 각 부분배열이 정렬된 상태이니, 각 부분배열의 앞에서부터 원소들을 가져온다면 작은 원소부터 가져올 수 있게 될 것입니다. 따라서, 각 부분배열의 앞에서부터 원소들을 비교하면서 더 작은 원소를 가져오면 될 것입니다! 그러면 각 부분배열이 정렬되어 있다는 사실을 적극적으로 활용하면서 전체 배열을 효율적으로 정렬할 수 있게 됩니다.
그림으로 병합 과정을 살펴보면 다음과 같습니다. 부분배열은 이미 정렬되어 있는 상태입니다.

각 부분배열의 앞에서부터 원소를 확인하면서 두 원소를 비교하여 작은 원소를 가져옵니다. 가져왔다면 그 부분배열에서는 다음 원소를 봐야할 것입니다. 이 과정을 반복하면 효율적으로 병합을 완료할 수 있습니다.

시간 복잡도를 계산하기 위해 이 알고리즘의 시간 복잡도를 $T(n)$이라고 하겠습니다. 부분배열의 길이는 $\dfrac{n}{2}$ 이므로 부분배열 $2$개를 정렬하기 위해서는 $2\,T\!\left(\dfrac{n}{2}\right)$ 만큼의 시간이 필요합니다. 그리고 부분배열 $2$개를 병합하는 과정에서는 각 부분배열의 원소를 모두 확인하게 되므로 $\mathcal{O}(n)$에 비례하는 시간이 들어갑니다. 이를 식으로 다음과 같이 나타낼 수 있습니다.
$$T(n) = 2T\left(\dfrac{n}{2}\right) + \mathcal{O}(n)$$
일종의 점화식 형태를 얻었는데, 이 점화식을 $T(n)$에 대하여 풀어주면 $T(n) \in \mathcal{O}(n \log n)$ 임을 얻습니다. (증명은 뒤에서 합니다.) $\mathcal{O}(n \log n)$ 만에 동작하는 알고리즘을 얻었습니다!
코드로 구현하면 다음과 같습니다.
잘 동작하지만, 위 코드에는 불필요한 동작이 많이 들어가 있습니다. 우선 부분배열을 만드는 과정(위 코드의 51~52줄)에서 불필요한 복사가 일어납니다. 언뜻 보기에는 그리 부담스러운 동작이 아닌 것처럼 보이지만, 위 코드의 실행 과정을 자세히 따져보면 merge_sort 함수가 호출될 때마다 인자로 넘겨진 배열 arr의 복사본이 생기는 것을 알 수 있습니다. 재귀적으로 구현했기 때문에, 재귀 깊이(recursion depth)만큼 arr를 복사하게 됩니다.
이를 최적화하기 위해 정렬하고자 하는 배열과 정렬 범위를 제한하는 식으로 구현하게 됩니다. 그러면 부분배열을 정렬하기 위해 정렬 범위를 $[0, n/2)$로 제한하여 불필요한 복사를 줄일 수 있습니다. 정렬 범위는 인덱스와 함수 인자로 처리하고, 이에 따라 코드 일부분이 수정되지만 전체적인 아이디어는 동일합니다. 코드로 구현하면 다음과 같습니다.
이 알고리즘을 사용하니 정수 $10$만개를 정렬하는데 148ms 밖에 소요되지 않았습니다. 약 150배 빨라졌습니다!
점화식 증명
$$T(n) = 2T\left(\dfrac{n}{2}\right) + \mathcal{O}(n)$$
에서 $\mathcal{O(n)}$ 항은 충분히 큰 상수 $c > 0$ 에 대하여 $cn$ 으로 대체할 수 있습니다. 따라서,
$$T(n) = 2T\left(\dfrac{n}{2}\right) + cn$$
을 풀면 됩니다. $n = 2^k$ 형태이므로, 이를 대입하면
$$T(2^k) = 2T(2^{k-1}) + c\cdot 2^k$$
이고 양변을 $2^k$ 로 나눈 뒤 $S(k) = T(2^k)/2^k$ 로 치환하면
$$\frac{T(2^k)}{2^k} = \frac{T(2^{k-1})}{2^{k-1}} + c \implies S(k) = S(k - 1) + c$$
가 되어 $S(k) = c(k - 1) + S(1) = c(k - 1)$ 임을 쉽게 알 수 있습니다. (등차수열) 따라서,
$$T(2^k) = 2^k \cdot S(k) = c(k-1) \cdot 2^k$$
이고, $n = 2^k$, $k = \log_2 n$ 을 대입하여 정리하면 $T(n) = cn(\log_2 n - 1) \in \mathcal{O}(n \log n)$ 입니다.
Quick Sort
퀵 정렬(Quick Sort)는 적당한 기준 원소(pivot)을 잡아 이 원소를 기준으로 배열을 분할하여 부분배열을 얻고, 각 부분배열을 정렬하는 알고리즘입니다. 아쉽게도 이 알고리즘은 이름과 동작 방식이 큰 관련이 없습니다.
우선 적당한 기준 원소(pivot element) p를 하나 잡습니다. 이제 부분배열을 만들기 위해 배열을 분할(partition)합니다. p 보다 작은 원소들은 p의 왼쪽으로, p보다 큰 원소들은 p의 오른쪽에 위치하도록 합니다. 그러면 p는 정렬되었을 때 자신의 위치에 존재하게 되므로 p의 왼쪽 부분배열, p의 오른쪽 부분배열을 각각 재귀적으로 정렬하면 배열 전체가 정렬됩니다.
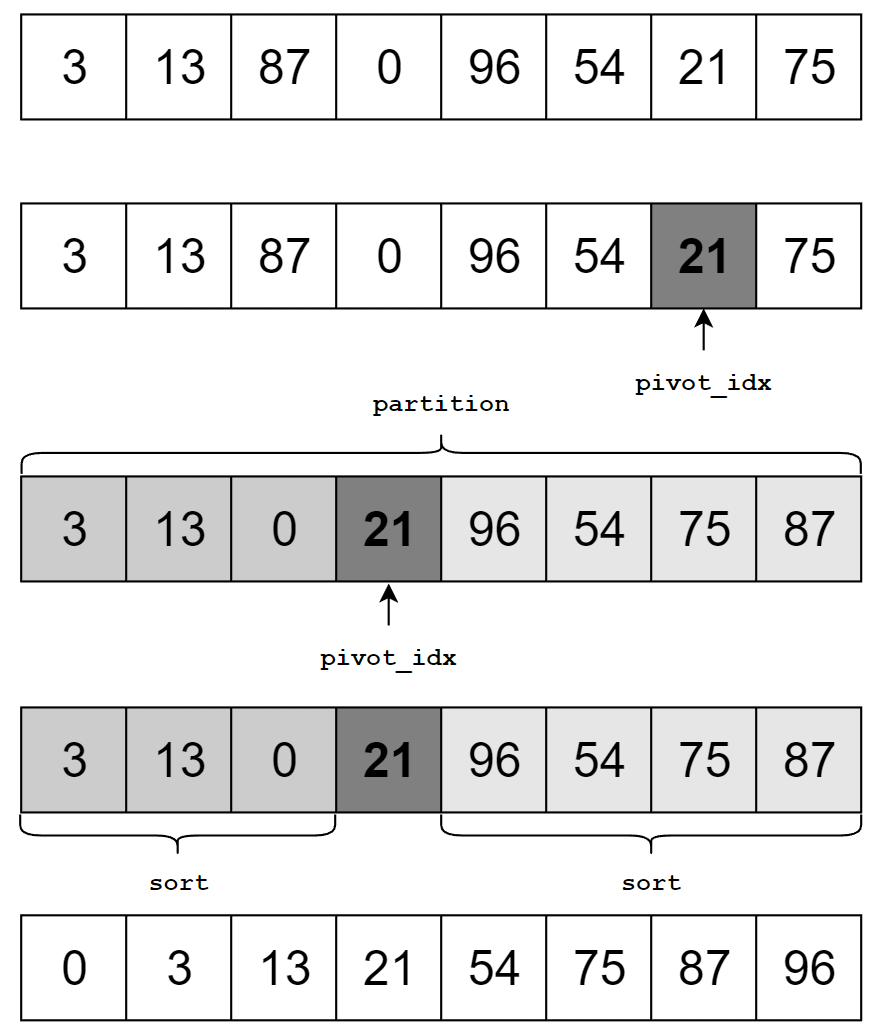
코드로 살펴보면 다음과 같습니다. 불필요한 복사 등을 막기 위해 정렬 범위를 제한하는 방식으로 구현했습니다.
여기서 자세히 살펴봐야 할 부분은 배열을 분할하는 partition과 기준 원소를 고르는 작업인 select_pivot 입니다.
분할 과정
분할도 효율적으로 해야 합니다! 우선 편의상 기준 원소는 배열의 맨 뒤로 보냅니다. 그리고 기준 원소보다 작은 원소가 몇 개인지 세는 count 변수를 사용합니다.
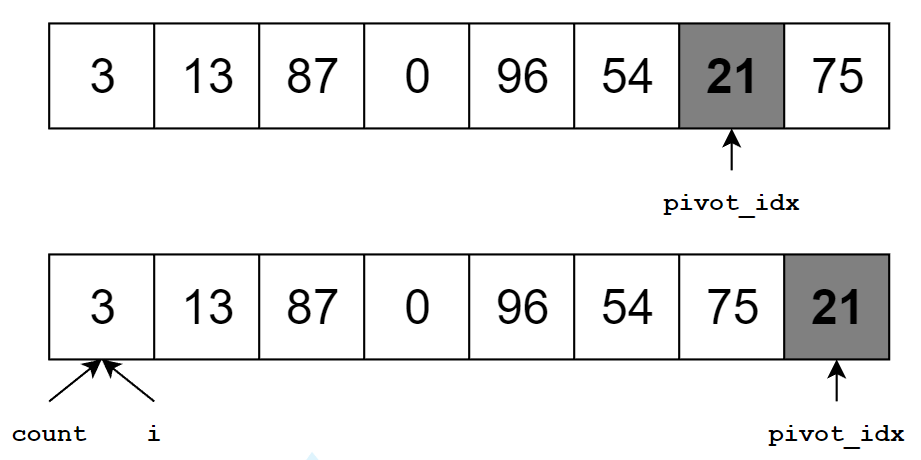
이제 배열의 맨 앞부터 원소 하나씩 확인하면서 기준 원소와 비교합니다. 만약 기준 원소보다 크다면 그냥 넘어가고, 기준 원소보다 작으면 count-번째 원소와 현재 원소의 자리를 바꿉니다. 그리고 count 의 값을 $1$ 증가시킵니다.
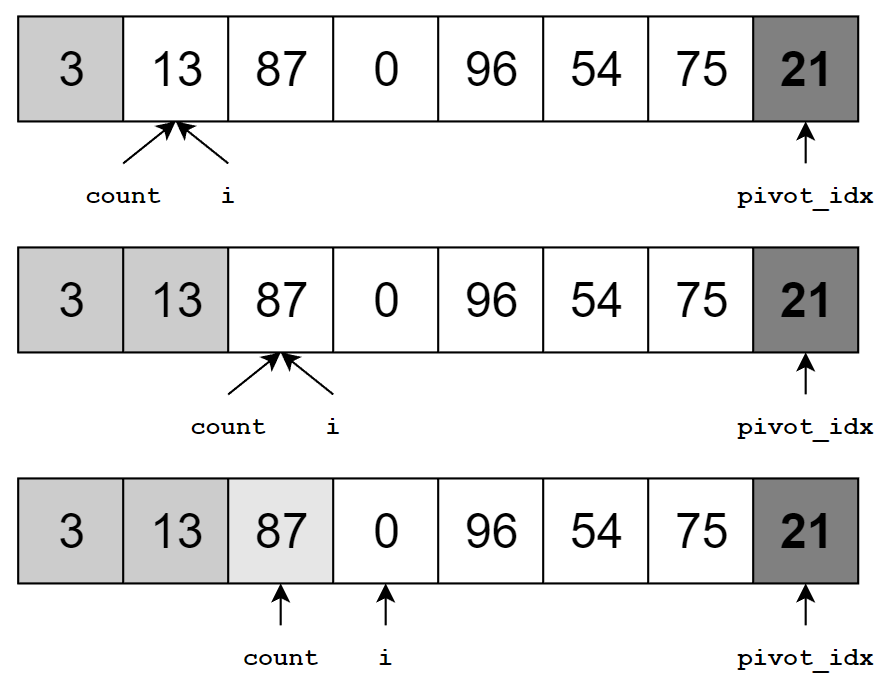
이렇게 하면 기준 원소보다 작은 원소가 몇 개인지 count 변수를 통해 알 수 있으며, 기준 원소보다 작은 원소가 나올 때마다 count-번째 원소와 자리를 바꿨기 때문에, 배열의 앞 count개 원소는 기준 원소보다 작은 원소들입니다. 마지막에는 기준 원소를 올바른 위치로 되돌려줍니다.
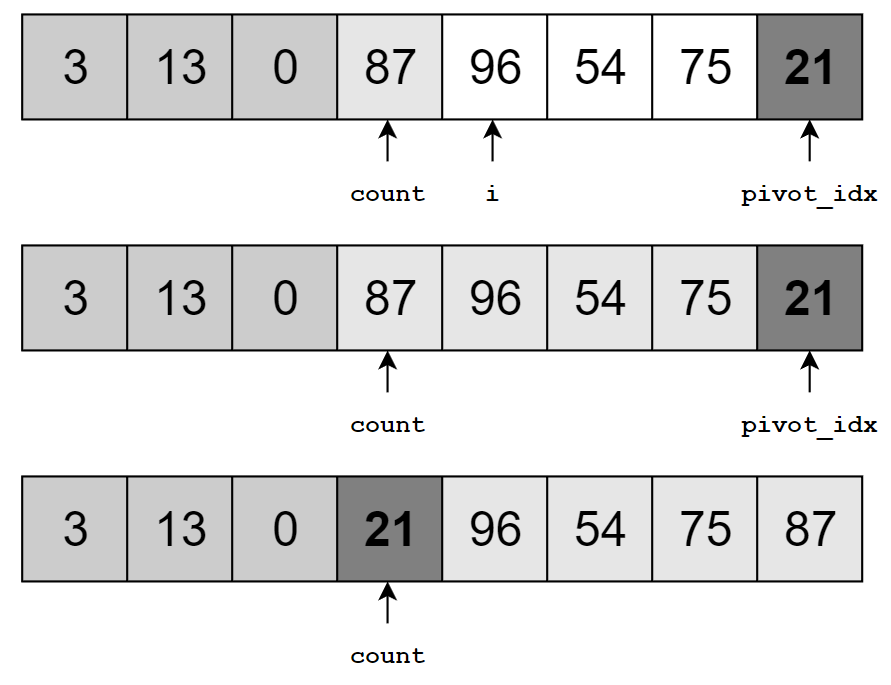
코드로 분할 과정을 살펴보면 다음과 같습니다. 편의상 설명은 중복된 원소가 없는 것처럼 했으나, 중복된 원소가 있더라도 기준원소와 대소를 비교하여 만약 같다면 자리를 바꿀지 말지 결정하면 됩니다. 정렬 결과나 시간 복잡도에는 영향을 주지 않습니다.
주어진 분할 범위 내의 원소가 $n$개일 때, 분할 과정의 시간 복잡도는 $\mathcal{O}(n)$ 입니다. 범위 내의 모든 원소를 한 번씩 기준 원소와 비교해야 합니다.
기준 원소의 선정
이제 기준 원소만 잘 선정하면 되는데, 기준 원소를 선정하는 정해진 방법은 없습니다. 어떤 원소를 고르더라도 위에서 설명한 분할 과정과 부분배열의 재귀적인 정렬 과정은 수행할 수 있기 때문입니다.
다만 기준 원소에 따라 분할의 결과가 달라지고, 두 부분배열의 길이가 달라질 수 있기 때문에 주의가 필요합니다. 분할의 결과로 얻은 두 부분배열의 길이는 전체 시간 복잡도에 영향을 주기 때문입니다!
퀵 정렬의 시간 복잡도를 $T(n)$이라 하고, 기준 원소의 정확한 위치가 $k$번째라고 가정하겠습니다. 그러면 분할에는 $\mathcal{O}(n)$ 시간이 소요되고, 부분배열의 길이는 각각 $k - 1$, $n - k$ 입니다. 부분배열을 각각 재귀적으로 정렬하면 $T(k - 1)$, $T(n - k)$ 시간이 소요되므로 다음 관계식이 성립합니다.
$$T(n) = T(k - 1) + T(n - k) + \mathcal{O}(n)$$
위 병합 정렬의 경우처럼 기준 원소가 잘 잡혀 부분배열의 길이가 각각 $\dfrac{n}{2}$ 로 비슷하게 분할된다면, 시간 복잡도가 $\mathcal{O}(n \log n)$이 됩니다. 하지만 운이 나빠 기준 원소가 배열의 최솟값 또는 최댓값으로 잡히게 되면 $k = 1$ 또는 $k = n$이 되고, 위 관계식은 다음과 같아집니다.
$$T(n) = T(n - 1) + \mathcal{O}(n)$$
예를 들어, 역순으로 정렬된 배열에서 기준 원소를 맨 마지막 원소로 잡는 경우가 이러한 경우입니다. 분할을 해도 부분배열의 길이가 $1$ 밖에 줄어들지 않아 엄청난 비효율을 초래하게 됩니다. 결국 원소 하나를 줄일 때마다 $\mathcal{O}(n)$ 시간이 들기 때문에 총 $\mathcal{O}(n^2)$ 만큼의 시간이 들어가게 됩니다.
이는 기준 원소를 아무리 랜덤으로 선정한다고 하더라도 운이 나쁘면 (극악의 확률로) 실제로 가능한 시나리오이며, 시간 복잡도는 최악의 경우까지 고려하기 때문에 퀵 정렬은 $\mathcal{O}(n^2)$ 입니다...
평균 수행 시간
하지만 현실에서 퀵 정렬은 생각보다 빨라 이름 값을 합니다. 퀵 정렬의 평균 수행 시간이 $\mathcal{O}(n \log n)$ 이기 때문입니다. 비록 최악의 경우 $\mathcal{O}(n^2)$ 이지만, 기준 원소를 랜덤으로 고르도록 하여 최악의 경우를 거의 피할 수 있으며, 평균적으로는 $\mathcal{O}(n \log n)$ 이기 때문에 꽤 빠른 편입니다.
최종 구현은 다음과 같습니다. 난수 생성은 다양하게 할 수 있습니다.
아래는 평균 수행 시간이 왜 $\mathcal{O}(n \log n)$ 인지 증명하는 과정입니다.
분할 과정에서는 기준 원소와 나머지 $n - 1$개 원소를 비교하고, 기준 원소로 가능한 경우는 $n$가지 이므로, 평균 수행 시간 $T(n)$을 계산하기 위해 다음 식을 세울 수 있습니다.
$$T(n) = \frac{1}{n} \sum_{k = 1}^{n} \big(T(k - 1) + T(n - k) \big) + n - 1 = n - 1 + \frac{2}{n}\sum_{k = 0}^{n - 1} T(k)$$
정리하면
$$nT(n) = n(n - 1) + 2 \sum_{k = 0}^{n - 1} T(k)$$
이고, 위 식의 $n$에 $n - 1$을 대입한 후 변변 빼면
$$nT(n) - (n-1)T(n-1) = n(n-1) - (n-1)(n-2) + 2T(n - 1)$$
을 얻고 이를 정리하면
$$nT(n) = (n + 1)T(n - 1) + 2(n - 1)$$
입니다. 양변을 $n(n+1)$로 나누어
$$\frac{T(n)}{n+1} = \frac{T(n - 1)}{n} + \frac{2(n-1)}{n(n+1)} \leq \frac{T(n-1)}{n} + \frac{2}{n+1}$$
를 얻습니다. 이 부등식을 반복 적용하면,
$$\frac{T(n)}{n+1} \leq \frac{T(n-1)}{n} + \frac{2}{n+1} \leq \frac{T(n-2)}{n-1} + \frac{2}{n} + \frac{2}{n+1} \leq \cdots \leq \frac{T(1)}{2} + \sum_{k = 2}^n \frac{2}{k + 1}$$
임을 알 수 있고, 이로부터
$$\frac{T(n)}{n+1} \leq \frac{T(1)}{2} + \sum_{k = 2}^n \frac{2}{k+1} \leq \sum_{k=1}^{n-1} \frac{2}{k} \leq 2 + \int_1^n \frac{2}{x},dx = 2 + 2\log n$$
이 되어 $T(n) \leq (n+1)(2\log n + 2)$ 로 $T(n) \in \mathcal{O}(n \log n)$ 임을 알 수 있습니다.
비교 기반 정렬의 하한
위 두 정렬 알고리즘에서는 부분배열을 $2$개 사용했습니다. 만약 $3$개, 혹은 그 이상의 부분배열을 사용한다면 시간 복잡도가 유의미하게 달라질까요? 아쉽게도 그렇지 않습니다. 사실, 비교를 사용하는 정렬 알고리즘의 시간 복잡도는 $\mathcal{O}(n \log n)$ 보다 더 좋을 수 없습니다. 즉, 비교 기반 정렬 알고리즘은 $\Omega(n \log n)$ 입니다.
정렬 알고리즘의 정렬 과정은 결정 트리(decision tree) 위에서의 탐색으로 생각할 수 있습니다. 임의의 배열에 대하여 루트(root) 노드에서 출발하여 정렬 알고리즘 과정에서 비교가 일어날 때마다 비교 결과에 따라 자식(child) 노드로 내려가는 과정으로 이해할 수 있습니다. 그리고 리프(leaf) 노드에 도달하면 정렬이 완료됩니다. 따라서, 이 트리에서 높이는 비교가 일어난 횟수로 생각할 수 있습니다.
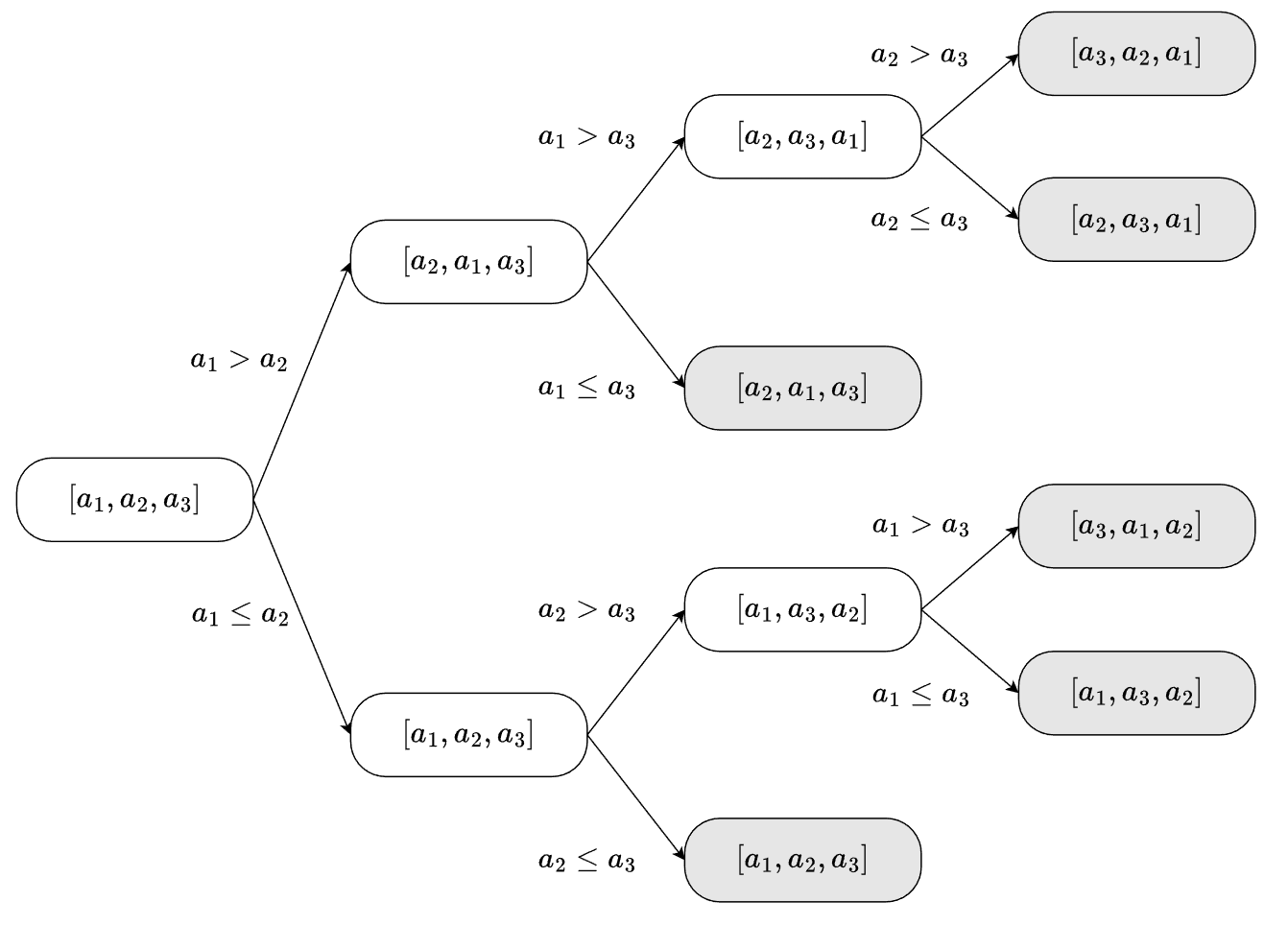
이제 비교 기반 정렬 알고리즘의 시간 복잡도 하한을 구하기 위해 위 결정 트리에서 높이의 하한을 계산하면 됩니다. 그런데 $n$개 데이터를 정렬한다고 하면, 정렬 결과로 가능한 경우의 수는 $n!$ 일 것입니다. 혹은 반대로, 비교를 사용하는 정렬 알고리즘이라면, 모든 $n!$가지 경우에 대해 정렬된 결과를 올바르게 찾아야 합니다.
그러므로 위 결정 트리의 리프 노드 수는 $n!$개이며, 이 때 결정 트리의 높이는 최소 $\log_2 n!$ 입니다. 그리고 스털링 근사에 의해
$$\log n! = n \log n - n + \Theta(\log n) \in \Theta(n \log n)$$
이므로 결정 트리의 높이는 $\Omega(n \log n)$이 되어 비교 기반 정렬 알고리즘도 $\Omega(n \log n)$임을 알 수 있습니다. 위에서 살펴본 병합 정렬과 퀵 정렬(평균적인 경우)은 최적의 정렬 알고리즘임을 알 수 있습니다!
지금까지 정렬 알고리즘을 소개하면서 편의상 예시로 정수를 정렬하는 경우를 들었지만, 사실 어떤 데이터 형태가 주어지더라도 대소 관계가 명확하게 정의되어 있다면, 위 정렬 알고리즘을 사용할 수 있습니다.
다음 글에서는 특별히 정수를 효율적으로 정렬하는 알고리즘에 대해 알아보겠습니다. 이 경우 $\mathcal{O}(n \log n)$ 이 아니라 선형 시간만에도 정렬이 가능합니다!
'정기연재 - 컴퓨터공학 > 자료구조와 알고리즘' 카테고리의 다른 글
| 5. Sorting (1) (0) | 2022.08.10 |
|---|---|
| 4. Linked List (0) | 2022.07.27 |
| 3. Arrays and Lists (0) | 2022.06.01 |
| 2. Asymptotic Notation (2) (0) | 2022.05.20 |
| 1. Asymptotic Notation (1) (0) | 2022.04.30 |




댓글