
4. Linked List
이번 글에서는 Linked List(연결 리스트) 자료구조에 대해 알아보겠습니다.
List 자료구조의 제약 조건
Array나 List 자료구조에서는 원소들이 메모리 공간 상에 연속적으로 존재해야 한다는 제약 조건이 있었습니다. 이 때문에 삽입/삭제를 수행하기 위해서는 빈 공간을 만들거나 없애야 했고, 삽입/삭제 위치 뒤에 있는 원소들을 모두 옮겨야 했습니다.
여기서 만약 '원소들이 메모리 공간 상에 연속적으로 존재해야 한다'는 제약 조건을 없애면 어떻게 될까요? List의 각 원소는 메모리 공간에 개별적으로 존재할 수 있게 하고, List의 다음 원소를 빠르게 찾기 위해 다음 원소의 메모리 주소를 가지고 있도록 구현할 수 있습니다.
Linked List 자료구조 소개
우선 Linked List의 각 원소들이 어떤 형태를 이루고 있는지 먼저 설명이 필요할 것 같습니다. 메모리 상에 원소들이 연속적으로 존재한다는 제약을 없앴기 때문에, 각 원소는 실제 자료 값과 다음 원소의 메모리 주소를 가지고 있어야 List 역할을 할 수 있습니다.
따라서 Linked List의 원소 하나는 다음과 같은 형태가 됩니다.

이를 ListNode라고 부릅니다. 코드로 나타내면 다음과 같습니다.
위와 같이 모든 원소가 다음 원소의 주소를 가지고 있다면, 우리는 첫 번째 원소의 주소만 알고 있으면 나머지 원소들을 차례로 찾아갈 수 있게 됩니다. 첫 번째 원소의 주소를 흔히 head 라고 표현하며, 최종적인 Linked List의 구조는 다음과 같습니다.

위와 같이 원소들이 서로 연결(link)되어 있기 때문에 Linked List (연결 리스트) 라고 부릅니다.
마지막 원소가 가리키는 곳은 null 으로, 다음 원소의 주소가 null 이면 Linked List의 끝에 도달했음을 알 수 있습니다.
현재 ListNode 코드는 다음과 같습니다.
Linked List의 연산
먼저 현재 LinkedList 의 코드를 살펴보겠습니다. 첫 원소의 주소를 가지고 있는 head 변수가 하나 필요할 것입니다. 그리고 구현 편의상 Linked List의 길이를 저장하는 size 변수도 하나 필요합니다.
이제 Linked List에서 검색(get), 수정(set), 삽입(add), 삭제(remove)를 어떻게 하는지 살펴보겠습니다.
검색
Linked List에서 \(i\)-번째 원소를 찾는 과정은 간단합니다. head 에서 시작해서, next 를 반복적으로 따라가면 됩니다. 단, 올바르지 않은 index에 대해서는 예외 처리가 필요합니다. 코드는 다음과 같습니다.
우선 올바르지 않은 index를 처리하기 위해, 주어진 index 가 현재 Linked List의 길이보다 크거나 같은지 검사합니다. 만약 그렇다면, index가 범위를 벗어났음을 의미하는 IndexOutOfBoundsException 을 던져 예외 처리합니다.
이제 Linked List의 시작 주소인 head 는 잃어버리면 안 되기 때문에 이를 복사하여 curr 라는 변수에 저장하고 이 값을 사용해서 연산합니다. index 만큼 next 를 타고 다음 원소로 이동하여, 해당 ListNode 의 value 를 돌려주면 됩니다.
지난 글에서 살펴본 Array나 List는 임의의 원소에 바로 접근할 수 있어 검색의 시간 복잡도가 \(\mathcal{O}(1)\) 이었지만, Linked List의 경우 head 부터 차례로 원소들을 하나씩 살펴봐야 하기 때문에 검색의 시간 복잡도는 \(\mathcal{O}(n)\) 입니다. ($n$: 원소 개수)
수정
원소의 수정도 간단합니다. $i$-번째 원소를 찾아가 값만 바꿔주면 됩니다. 검색의 구현과 마찬가지로 예외를 처리합니다.
검색과 마찬가지로, $i$-번째 원소까지 가서 값을 수정해야 하기 때문에 시간 복잡도는 $\mathcal{O}(n)$ 입니다. ($n$: 원소 개수)
삽입
삽입은 조금 복잡합니다. 새로운 ListNode 를 추가하면서 다음 원소의 주소를 변경해야 하기 때문입니다. 코드를 통해 확인해보겠습니다.
우선 index가 올바르지 않으면 예외를 던지는 부분은 동일합니다. 단, Linked List의 맨 뒤에 삽입하는 경우도 있으므로 위 검색/조회 연산과는 달리 조건에서 등호가 빠져 index > size() 로 비교해야 합니다.
그리고 원소를 추가하는 것이므로 size 를 1 증가시켜야 합니다. 이제 원소 삽입 연산은 2가지 경우로 나뉩니다.
먼저 Linked List의 맨 앞에 원소를 삽입하려는 경우(index == 0), head 에 바로 원소를 추가해주면 끝입니다.
이외의 경우에는 삽입하려는 위치의 바로 앞 원소까지 따라갑니다. 코드에서는 이 원소를 curr 라고 했습니다. curr 의 다음 원소 주소는 새로운 원소의 주소로 덮어씌워질 예정이므로, 미리 다음 원소의 주소를 저장해둬야 합니다. 이는 nextElement 에 저장되어 있습니다. 그리고 새로운 원소 newElement 를 만드는데, 새로운 원소의 다음 원소가 nextElement 가 되도록 합니다. 이제 curr 의 다음 원소가 newElement 가 되도록 설정해주면 끝입니다.
이 과정을 그림으로 확인하면 다음과 같습니다.
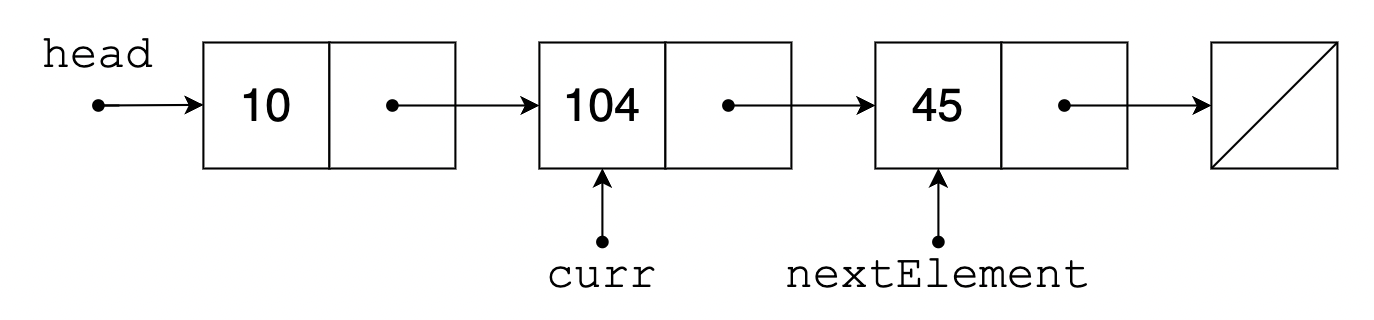


Array 또는 List와 달리 원소를 삽입할 때 삽입 위치 뒤의 모든 원소들을 한 칸씩 밀어주지 않아도 된다는 장점이 있지만, 결국 삽입 위치까지 이동한 다음 삽입하기 때문에 시간 복잡도는 $\mathcal{O}(n)$ 으로 변하지 않았습니다. ($n$: 원소 개수)
삭제
마지막으로 삭제 연산입니다. 원소를 지운 뒤 남아있는 원소들이 제대로 연결 되도록 '다음 원소 주소'를 잘 설정하면 됩니다.
삽입 연산 코드와 거의 유사함을 확인할 수 있습니다. 우선 잘못된 index로 삭제가 일어나지 않도록 예외 처리를 해줍니다.
그리고 원소가 삭제되므로 size 를 1 감소시켜야 합니다. 마찬가지로 삭제 연산도 2가지 경우로 나뉩니다.
먼저 Linked List의 맨 앞 원소를 삭제하려는 경우(index == 0), head 를 head 의 다음 원소로 설정하면 끝입니다.
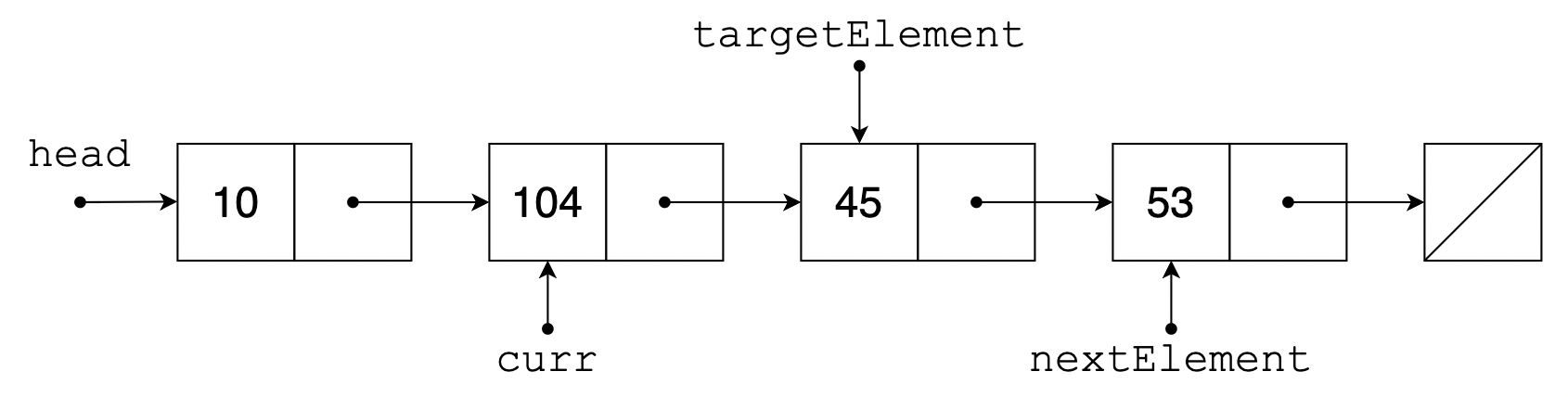
이외의 경우에는 삭제하려는 위치의 바로 앞 원소까지 따라갑니다. 마찬가지로 코드에서는 이 원소를 curr 라고 했습니다. 이제 삭제하려는 원소 targetElement 는 curr 의 다음 원소가 될 것이며, 삭제가 일어나면 targetElement 의 다음 원소 nextElement 가 curr 의 다음 원소가 될 것입니다. 따라서 curr 의 다음 원소를 nextElement 로 설정하면 끝입니다.
이 과정을 그림으로 확인하면 다음과 같습니다.
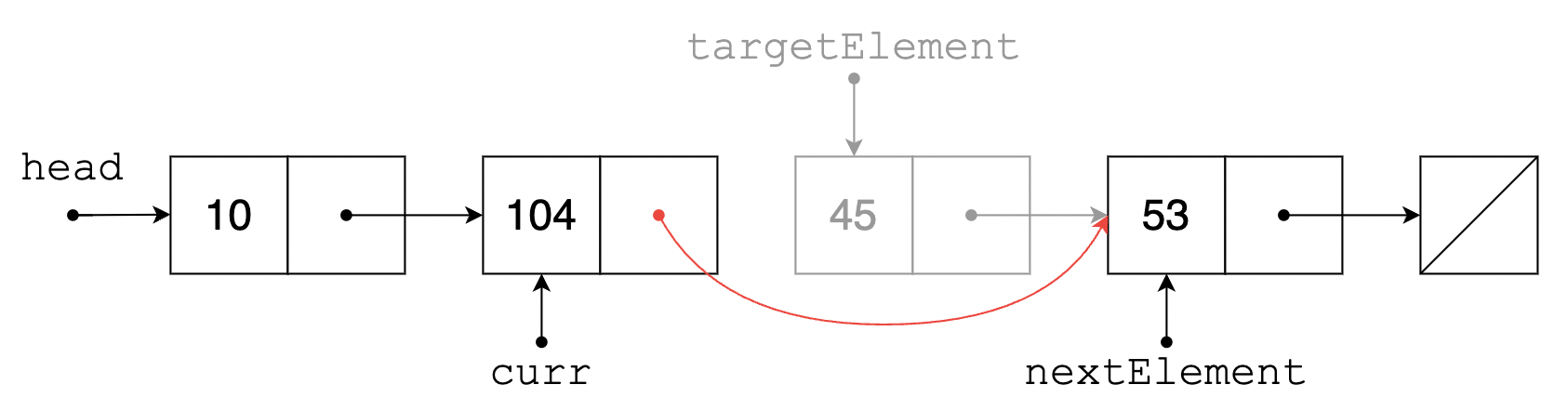
마찬가지로 삭제 연산의 시간 복잡도는 $\mathcal{O}(n)$ 으로, Array 또는 List의 삭제 연산 시간 복잡도와 동일합니다. ($n$: 원소 개수)
Doubly Linked List
Linked List 자료 구조는 현재 원소에서 다음 원소로만 갈 수 있다는 아쉬운 점이 있었습니다. 이 점을 보완하여, 현재 원소에서 이전 원소와 다음 원소로 모두 갈 수 있는 Doubly Linked List 를 구현할 수도 있습니다.
Doubly Linked List 는 이전/다음 원소와 모두 연결되어 있으므로 'Doubly'라는 이름이 붙었습니다. 각 원소의 형태는 다음과 같습니다.

기존 Linked List와 비교했을 때 연산 측면에서 시간 복잡도는 거의 동일하다고 봐도 무방합니다. 하지만 현재 원소에서 앞/뒤로 모두 이동할 수 있다는 자유도를 얻었습니다! (물론 이전 원소의 주소를 저장하기 위한 추가 메모리를 대가로 바쳤습니다)
경우에 따라 head 의 prev 를 마지막 원소로, 마지막 원소의 next 를 head 로 설정하여 맨 뒤에 원소를 추가하는 연산의 시간 복잡도를 $\mathcal{O}(1)$ 로 만들 수도 있습니다.
Doubly Linked List의 연산 또한 결국 이전/다음 원소들의 메모리 주소만 잘 연결해주면 되기 때문에, 구현은 기존 Linked List와 본질적으로 동일합니다. 따라서 코드는 생략하고, 실제 문제에서 확인해보도록 하겠습니다.
응용 문제: 에디터
간단한 에디터를 구현하는 문제입니다. 처음에 문자열이 주어지고, 커서의 위치가 주어진 다음 커서를 움직이는 연산, 문자 삭제, 문자 입력을 구현해야 합니다.
요구사항 자체는 간결하고 명확한데, 시간 제한이 0.3초로 매우 짧습니다. 만약 이 문제를 Array나 List로 해결하려고 한다면, 시간 제한 안에 결과가 나오기는 힘들 것입니다.
위에서 분명 Linked List의 삽입/삭제는 시간 복잡도가 $\mathcal{O}(n)$ 으로, Array나 List에 비해 좋아지지 않았습니다. 하지만, 연속으로 원소를 삽입하거나 삭제한다면 이야기가 달라집니다. 이 문제에서와 같이 현재 커서 위치에서 (혹은 커서를 이동하더라도) 여러 번 문자를 입력하거나 삭제하게 된다면 Array나 List의 경우 커서 뒤에 있는 문자들을 한 칸씩 밀거나 당겨줘야 합니다. 만약 커서가 맨 앞에 있고 여기서 계속 새로운 문자열이 입력된다면, 최악의 경우 $\mathcal{O}(n^2)$ 회의 연산이 일어날 수 있게 됩니다. 하지만 Linked List로 구현한다면, 커서의 첫 위치로 이동한 뒤부터는 현재 위치에서 새로운 원소만 추가하면 끝이기 때문에 훨씬 효율적으로 처리할 수 있습니다.
이 문제에서는 커서가 앞/뒤로 모두 이동할 수 있기 때문에 Doubly Linked List를 사용해야 하며, 나머지 구현은 커서가 맨 앞 또는 맨 뒤인 경우만 잘 예외 처리해주면 어렵지 않게 해결할 수 있습니다.
'정기연재 - 컴퓨터공학 > 자료구조와 알고리즘' 카테고리의 다른 글
| 6. Sorting (2) (1) | 2022.08.18 |
|---|---|
| 5. Sorting (1) (0) | 2022.08.10 |
| 3. Arrays and Lists (0) | 2022.06.01 |
| 2. Asymptotic Notation (2) (0) | 2022.05.20 |
| 1. Asymptotic Notation (1) (0) | 2022.04.30 |




댓글