
안녕하세요! 저는 공우 14기 서민균입니다. 지난 학술세미나에서 ChatGPT에 관한 발표를 했었는데, 그 내용을 공유해 드리고자 합니다. 우선 ChatGPT가 등장하기까지의 과정과 GPT-1~3이 어떻게 학습되었는지를 간단히 살펴볼 것입니다. 이후 이번 글의 하이라이트인 InstructGPT (GPT-3.5)와 ChatGPT가 어떻게 학습되었는지를 알아보도록 하겠습니다.
ChatGPT란?
ChatGPT란 "대화형 인공지능 모델"입니다. GPT는 Generative Pre-trained Transformer의 약자로 "사전에 학습된 대규모 데이터를 활용하여 자연어 생성 및 다양한 자연어 처리 작업에 사용되는 모델"을 일컫습니다. 여기서 Transfomer가 무엇일지 의문이 들 것입니다. Transformer는 NLP를 비롯한 딥러닝 전반에 지대한 파급력을 행사한 아키텍처로, ChatGPT 타임라인에서 더 자세히 다루도록 하겠습니다.
Fine-tuning
본격적으로 시작하기에 앞서 본 글에서 Fine-tuning이라는 개념이 종종 등장하는데 이에 대해 간략히 설명하겠습니다. Fine-tuning은 이미 학습된 Source model을 사용자의 용도에 맞게 새로운 데이터셋으로 추가 학습시켜 Target model로 변환하는 과정입니다. 매번 새로운 모델을 학습시키기엔 데이터와 컴퓨팅 파워가 부족하다는 문제가 있습니다. 따라서 기존에 학습된 대형 모델들로부터 얻을 수 있는 정보들을 최대한 활용하고자 fine-tuning을 종종 활용하곤 합니다.

Ex) Source model: 음식 데이터셋으로 학습된 대규모 모델 / Target model: 한식 분류 모델
ChatGPT 타임라인

ChatGPT가 등장하기까지 위와 같은 이벤트들이 있었습니다. 이를 하나하나 살펴보도록 하겠습니다.
OpenAI 설립 (2016)
ChatGPT는 2016년 설립된 OpenAI라는 단체에서 개발됐습니다. OpenAI는 인공지능이 빅테크 기업의 산물로 남는 것을 방지하기 위해 인공지능 관련 정보를 공개하여 인류에게 이익을 줄 것을 목표로 공동으로 인공지능 발전을 추구하고자 하는 의도에서 설립된 단체입니다. "Open"에서 이 단체의 설립 취지를 유추해 볼 수 있습니다. (단, 지금의 행보가 OpenAI라는 이름에 걸맞은 지는 잘 모르겠습니다.)
Attention is All You Need (2017)
이후 2017년 Google에서 딥러닝 역사에 한 획을 긋는 논문을 출시합니다. High performance를 달성할 때 RNN, CNN과 같은 요소가 필요하지 않고 Attention 메커니즘만 필요하다는 "Attention is All You Need"라는 제목과 함께 Transformer 아키텍처를 최초로 고안한 논문입니다. 기존의 sequence 변환을 수행하던 모델들은 각각의 한계점들이 있었습니다. 시계열 데이터를 다루다 보니 병렬작업이 불가능해 컴퓨팅 측면에서 치명적이었으며, vanishing gradient 및 정보 손실 문제 등이 있었습니다. 이를 어느 정도 해결한 것이 attention 메커니즘인데, 사실 이는 2015년에 이미 등장한 방법론입니다. 허나 당시엔 RNN 계열의 모델과 함께 사용했었는데, 구글에서 제시한 transformer 아키텍처는 attention 메커니즘만으로도 높은 성능을 보일 수 있음을 증명하며 병렬처리가 용이해 학습이 빠르다는 장점이 있습니다.

GPT & GPT-2 (2018~2019)

구글의 논문 발표 후 Transformer와 비지도 학습을 결합한 태초의 GPT가 탄생했습니다. GPT 모델은 대상에 대한 별도의 지시 없이 스스로 데이터의 패턴을 파악해 학습을 진행해 나갔는데, 온전한 비지도 학습이라 부르기에는 fine-tuning 단계에서는 지도학습이 필요했습니다. 학습 데이터는 약 5GB로 주로 책의 데이터를 사용했으며, GPT-1 모델의 파라미터 수는 1,700만 개였습니다. 딥러닝 모델의 파라미터 수가 성능과 항상 비례하지는 않지만, 언어 모델에서는 통상적으로 파라미터 수와 성능이 비례하는 경향이 있습니다.

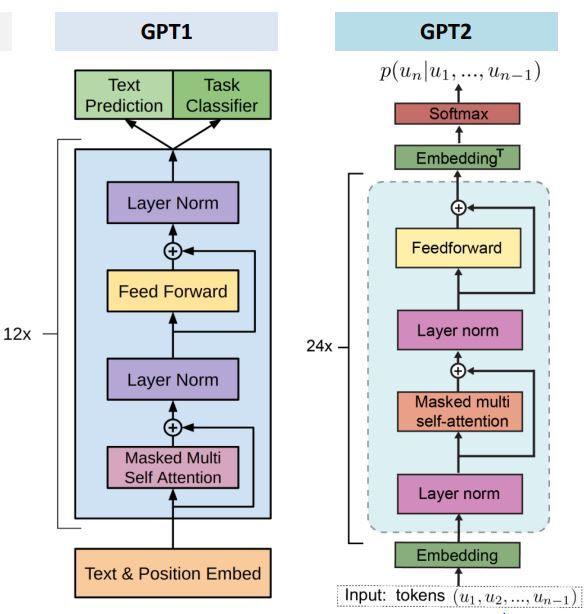
이후 짧은 간격을 두고 GPT-2가 출시됐습니다. GPT 1의 업그레이드 버전으로 앞서 fine-tuning 과정에서의 지도학습 과정이 생략되었으며, Zero-Shot learning을 통해 별도의 훈련 없이 새로운 작업을 수행할 수 있게 됐습니다. 학습 데이터는 40GB로 훨씬 늘어났으며, Web Text를 기반으로 학습됐습니다. 파라미터 수도 15억 개로 증가했습니다.
* Zero-shot learning: 모델이 별도의 학습 없이 새로운 작업을 수행할 수 있는 능력
Ex) 영어로 작성된 문서를 요악하는 방법을 학습한 모델을 프랑스어로 작성된 문서를 요약하는 데 사용
GPT-3 (2020)
GPT-2의 파라미터 수가 15억 개였습니다. 과연 GPT-3의 파라미터 수는 몇 개였을까요? 무려 1,750개로 기존의 100배 이상으로 증가했습니다. Self-attention layer를 기존 모델에 비해 훨씬 많이 쌓았으며, 학습 데이터도 무려 600GB로 엄청나게 증가했습니다.
* Self Attention: 입력한 문장 내의 각 단어를 처리해 나가면서 문장 내의 다른 위치에 있는 단어들을 보고 힌트를 받아 현재 타겟 위치의 단어를 더 잘 인코딩할 수 있게 하는 과정. 이 단어가 앞의 단어와 어느 정도 연관성이 있는가를 활용.
앞서 파라미터 수가 증가하면 모델의 성능도 덩달아 좋아진다고 언급했었는데요, GPT-3 모델은 인간의 언어 능력에 근접한 자연스러운 문장 생성 능력을 선보였으며, 특정 작업에서는 인간 수준을 뛰어넘는 성능을 보였습니다. GPT-3은 질의응답, 대화 생성, 문장 완성, 번역, 코딩, 글 요약 등 다양한 자연어 처리 작업을 수행할 수 있습니다. 또한 다양한 언어를 지원하며 이전 버전들 보다 훨씬 더 많은 언어를 지원합니다.

근사해 보이지만 GPT-3에는 사실 명확한 한계가 있었습니다. 바로 인터넷에서 수집한 텍스트로 학습되었다는 점입니다. 무려 600GB의 텍스트 데이터를 구할 수 있다는 점에서 웹은 매우 매력적인 선택지이지만, 온갖 허위 정보와 편견을 받아들여 학습된 GPT-3는 사용자의 의도 및 가치와 부합(allign) 되지 않은 응답을 하곤 했습니다. 이후 GPT-3의 편향성, 인공지능의 유해성, 윤리 등의 문제가 부각됐습니다.
InstructGPT (2022)
앞서 GPT-3의 한계를 살펴봤습니다. 이를 극복하고자 OpenAI에서는 모델이 잘못된 정보나 불쾌감을 유발하는 텍스트를 생성하지 않도록 RLHF를 도입해 InstructGPT를 만들었습니다. InstructGPT는 최초에 불린 명칭이며 추후 추가 학습이 진행되면서 GPT-3.5로 불리게 됐습니다. InstructGPT는 ChatGPT의 쌍둥이 모델로 불리는 만큼 학습 과정이 매우 유사합니다. 이를 앞선 GPT 1~3보다 자세히 살펴보겠습니다.
RLHF: Reinforcement Learning from Human Feedback
인간의 피드백을 통해 강화 학습을 수행하는 기술. 기존의 강화 학습은 보상 함수를 설정하여 시스템이 스스로 보상을 최대화하는 방식으로 학습을 진행하는데, 보상 함수를 정확히 설정하기가 어려운 문제가 있습니다. 이러한 문제를 해결하기 위해 RLHF는 인간의 피드백을 이용하여 시스템이 보상을 최적화하도록 하는 방식으로 학습합니다.
GPT-3에 인간 평가단의 피드백을 반영하여 훈련시킨 결과 탄생한 InstructGPT는 사용자의 지시를 더 잘 따랐습니다. 또한 InstructGPT에서는 불쾌감을 주는 언어 혹은 잘못된 정보를 생성하거나, 실수를 저지르는 경우가 전반적으로 감소했습니다. 요컨대 InstructGPT는 이용자가 요구하지 않는 한 나쁜 말을 하지 않음을 확인할 수 있습니다.

GPT-3와 InstructGPT가 생성한 응답을 비교해 보면 InstructGPT가 직관적으로 사용자 질문에 더 적합한 응답을 생성하는 것을 확인할 수 있습니다. 또한, RLHF의 적용 이후 답변의 정확도와 안정성이 급증했습니다. 유해한 응답을 덜 생성했으며 사실에 기반한 응답을 더 생성했습니다.
이제 InstructGPT의 학습 과정을 자세히 살펴보겠습니다.

Step 1: SFT (Supervised Fine-Tuning)
가장 먼저 할 일은 고객이 API에 제공한 프롬프트를 샘플링하여 프롬프트 목록을 정하는 것입니다. 이후 샘플링된 프롬프트에 대해 Human Labeler는 모델 output에 대한 이상적인 설명을 수기로 작성합니다. 이때 사람이 직접 라벨링 하므로 고비용으로 볼 수 있습니다.
이 데이터는 고품질 큐레이션 데이터셋으로 지도학습을 통해 GPT-3을 fine-tuning 할 때 사용됩니다. InstructGPT의 학습은 GPT-3을 fine-tuning 하면서 시작됩니다.
Step 2: RM (Reward Model)
강화학습에서 Reward model은 에이전트가 자신의 행동의 성공 또는 실패에 대한 피드백을 제공하는 중요한 구성 요소입니다.

앞서 선택된 프롬프트 목록에 대해 step1에서 학습한 SFT 모델이 각각 여러 개의 아웃풋을 생성합니다. 이후 Human Lab eler는 어떤 아웃풋이 이프롬프트에 대해 가장 적합한지 순위를 매깁니다. 이를 통해 Labeling이 지정된 새로운 데이터셋이 생성됩니다. 인간이 문장을 처음부터 생성하는 것보다 훨씬 쉽기 때문에 효율적으로 많은 양의 데이터를 만들 수 있으며, 그 결과 이 데이터셋은 SFT 모델에 사용된 것의 약 10배 크기입니다.
이 데이터는 Reward Model을 학습하는 데 사용됩니다.
Step 3: PPO (Proximal Policy Optimization)

ChatGPT (2022)

InstructGPT가 ChatGPT의 sibling model이라는 얘기를 했었는데, 학습 과정도 매우 유사합니다. InstructGPT는 지시 사항을 따르는 작업에 특화된 반면 ChatGPT는 대화형 AI 및 자연어 처리 작업에 사용되는 언어 모델입니다. 따라서 GPT-3.5에서 fine-tuning을 더 진행해 만들었습니다.
InstructGPT는 인간의 요청에 대한 AI 에이전트의 반응을 데이터로 생성했지만, ChatGPT는 양방향의 대화가 이뤄져야 하므로 인간과 AI 에이전트 양쪽의 대화 데이터를 생성했습니다. 외에 과정은 InstructGPT와 동일합니다.
ChatGPT는 InstructGPT (GPT-3.5)의 fine-tuning 모델이며, InstructGPT는 GPT-3의 fine-tuning 모델입니다. 즉, ChatGPT의 학습 과정은 사실 GPT-3의 학습과정까지 포함된다고 볼 수 있습니다. 하지만 본 글에서는 이를 자세히 다루지 못했습니다. 관심 있으신 분들은 아래 링크의 OpenAI의 paper를 참고해 보시면 좋을 것 같습니다.
https://openai.com/research?models=gpt-3
글을 마치며
요즘 분야를 막론하고 많은 분이 ChatGPT를 사용하는 것 같습니다. 출시 두 달 만에 월간 사용자가 무려 1억 명을 돌파했다고 해요. 2021년 그림 생성 AI인 DALL-E가 등장했을 때 사람들 모두 기술적 혁신에는 감탄했지만, 일반인들이 쓸 일이 많지는 않다는 평이 있었습니다. 그로부터 약 1년 후 ChatGPT가 등장했고, AI가 우리 삶에 얼마만큼 영향력을 미칠 수 있는지 여실히 보여주는 중이라 생각합니다.
2023년 3월 GPT4가 공개됐으며, 이를 탑재한 bing, MS의 Office 등이 공개됐습니다. 또한 ChatGPT plugin을 활용해 유명 기업들이 대화형 서비스를 제공하기 시작했으며, ChatGPT를 기반으로 한 스타트업 수도 급증했다고 합니다. 이제는 빠른 시일 내에 AI가 우리 일상 깊숙이 자리 잡을 것으로 예상됩니다.
여러분들은 AI의 발전에 대해 어떻게 생각하시나요? 저는 경외감이 느껴집니다. 매년 급변하는 시장이 흥미로우면서도 발전 속도가 너무 빨라 두려움도 함께 느껴지는 것 같습니다. 앞으로는 또 어떤 AI 모델들이 우리를 놀라게 할까요?
이상으로 긴 글 읽어주셔서 감사합니다 :)
'STEM - 학술세미나 > 컴퓨터공학' 카테고리의 다른 글
| DeepMind 논문으로 보는 강화학습의 기초 (0) | 2023.09.01 |
|---|---|
| 컴퓨터공학과: 넥슨 본사에서 넥슨 게임을 키다...! Vol. 2 (0) | 2022.12.24 |
| 3D 렌더링에 인공지능을 어떻게 사용할까? (2) | 2022.04.12 |
| 딥러닝 모델의 정확도 올리기 (4) | 2022.02.18 |
| 딥러닝을 활용하여 입술 모양을 단어로 추측하기 (2) | 2022.02.08 |




댓글