
안녕하세요. 공우 11.5기 이태균입니다. 앞서 많은 분들이 딥러닝에 대한 글을 적어주셨는데요, 이에 관련된 색다른 주제에 대해 간략하게 소개해보려고 합니다.
2022년 현재, 세상에는 수 많은 딥러닝 모델들이 있습니다. 이미지를 분류하는 CNN 모델부터 텍스트 데이터를 처리하는 RNN, transformer 모델, 그리고 알파고를 통해서 유명해진 강화학습 모델 등등 많은 형태의 실용적인 연구들이 있습니다. 그런데 딥러닝 모델은 왜 수렴하는 걸까요?
이에 관해 다루고 있는 Stanford 대학원 강좌인 Stanford 229m의 Lecture Note를 읽고 인상적인 부분들을 일부 발췌해서 소개하도록 하겠습니다. 구글에 검색하시면 누구나 쉽게 접근할 수 있습니다.
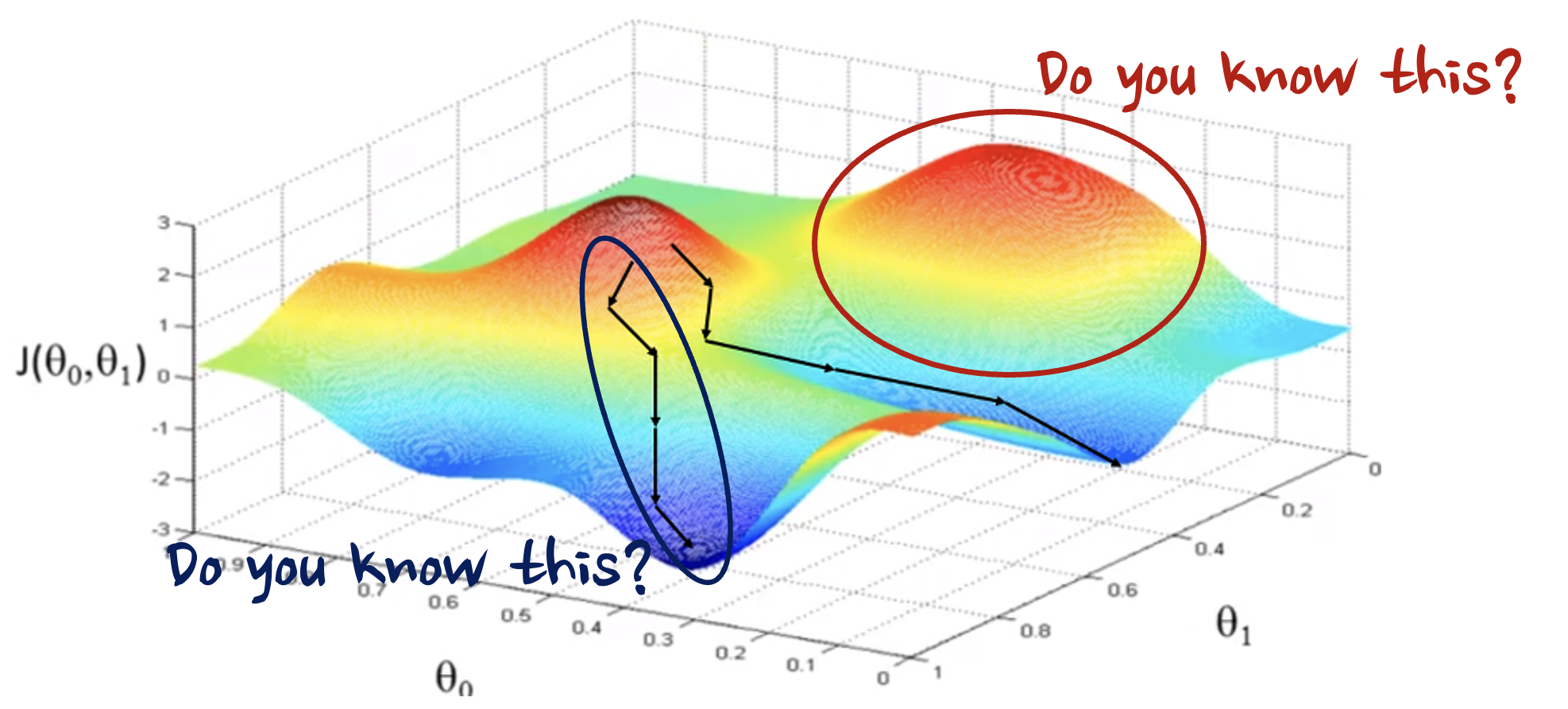
우리는 보통 Loss function을 정의하고, Gradient Descent를 통해서 Loss function이 존재하는 공간 상에서 경사를 따라 내려가면서 local minimum을 구한다고 대략적으로 생각하는데요, 이러한 사고 과정에는 많은 비약이 있습니다.
- 실제로 수렴을 한다는 보장이 없고
- N개의 데이터 샘플에만 접근이 가능하며(데이터의 분포 함수를 추측만 할 수 있지 알 수는 없습니다)
- 수렴을 한 지점이 local minima을 넘어서 global minima라는 보장이 없습니다.
그래서 이런 이론적인 비약을 채워나가는 것이 바로 ML theory 분야입니다. 이러한 논의의 시작을 위해서 간단하게 식을 세워보겠습니다.
Supervised Learning을 가정했을 때(Loss function을 $L$, input을 $x$, output을 $y$, model을 $h_\theta$라 하겠습니다)
Loss function은 $L(h) = \mathbb{E}_{(x,y) \sim p} [\ell(h(x),y)] $ 와 같이 정의될 수 있습니다.
이 $L(h)$ 를 예측한 값인 $\hat{L}(h_\theta)$의 경우 $\mathbb{E}_{(x^(i),y^(i)) \sim P}[\hat{L}(h_\theta)] = L(h_\theta)$ 로, 평균을 취했을 때 원하는 loss function이 된다는 사실은 알 수 있습니다.
하지만 일반적으로 $\hat{L}(h_\theta) \approx L(h_\theta)$ 라고 할 수 있을까요?
또한, $\theta$ 라는 parameter 또한 모델을 설계할 때 추정을 하게 되는데, 일반적으로 $L(h_\hat{\theta}) \approx L(h_\theta)$ 라고 할 수 있을까요? 이러한 물음들을 던집니다.
Lecture Note 2단원에서는 이러한 사실을 증명합니다.
$L(\hat{\theta}) - \inf_{\theta \in \Theta}{L(\theta)} \leq \frac{c}{n} + o(\frac{1}{n})$이 됩니다.
즉, $n$이 충분히 커진다면 $L(\hat{\theta})$와 $L(\theta)$의 최솟값의 차이를 bound할 수 있다고 말하고 싶어합니다. 하지만 이렇게 계산이 마냥 간단하지는 않습니다. $o(\frac{1}{n})$항에는 n과 관련 없는 매우 큰 상수가 곱해져 있을 수도 있기 때문에, $L(\hat{\theta})$와 $L(\theta)$의 최솟값의 차이가 bound된다고 하기에는 비약이 조금 있어 보입니다.
따라서, $n$이 $\infty$가 된다는 가정을 버리고 $L$ 함수의 uniform convergence를 보이는 쪽으로 접근을 하게 됩니다.
여기까지가 미리보기였습니다. 관심이 있으신 분들은 CS229m Lecture note와 youtube 영상을 찾아보시는 것을 추천드립니다.
이대로 끝내긴 아쉬우니, 7단원에서 제기된 딥러닝의 이론적 미스테리들에 대해서 하나씩 짚고 넘어가겠습니다. 아직 딥러닝에서는 발견된지 얼마 되지 않았고 이론적으로도 설명하기 어려운 현상들이 있습니다.
첫 번째는 Neural Tangent Kernel(NTK)의 수렴성입니다. NTK에 대해서 자세히 설명하지는 않겠지만, 대략 다른 공간으로 함수를 이동시켜서 Gradient Descent를 진행한다고 보시면 됩니다. NTK는 특정한 hyperparameter에서만 매우 까다롭게 수렴하는데, 아직 이에 대한 설명이 충분히 이뤄지지 않았습니다.
두 번째로 Implicit Regularization Effect가 있습니다. 얻어진 parameter 해 $\hat{\theta}$는 적은 복잡도를 지니고 있어서 쉽게 일반화가 되는 좋은 성질이 있는데, 이를 내재되어 있는 규제라고 볼 수 있습니다. 하지만 이 또한 왜 존재하는지 명확하게 수식으로 설명하지 못했습니다.
이 외에도 강화학습의 이론적인 수렴성에 대해 논의한 Cornell CS 6789등의 강좌가 있으니 관심이 있으신 분들은 꼭 찾아보셨으면 좋겠습니다.
개괄적인 소개가 도움이 되었으면 좋겠네요. 감사합니다!
'STEM - 학술세미나' 카테고리의 다른 글
| STEM - 학술세미나 게시판이 신설되었습니다. (0) | 2019.11.02 |
|---|
댓글